观点摘要
01、在经过三个月的酝酿与完善后,完成了国家互联网信息办公室审议,国家发展和改革委员会、教育部、科学技术部、工业和信息化部、公安部、国家广播电视总局七部委同意的立法进程,《生成式人工智能服务管理暂行办法》成为全球第一个全面监管生成式人工智能的立法文件。
02、《暂行办法》相较之《征求意见稿》进一步明确以及限缩了适用范围:向中华人民共和国境内公众提供生成式人工智能服务。具体判断是否适用《暂行办法》,需要注意三个关键词,分别是“面向中国境内”“面向公众”“提供服务”。
03、经过分析,我们认为《暂行办法》下技术支持者与服务提供者均受到同样的监管要求。
04、《暂行办法》针对应用层重点鼓励生成积极健康的优质内容上,而对技术层和基础层主要在促进加速基础设施(算力、数据等)建设以及鼓励平等的国际合作,参与国际标准制定。
05、《暂行办法》尚未建立如欧盟《人工智能法案》近似的分级监管体系,一个重要的原因可能在于,立法者将这一任务留给了未来要制订的《人工智能法》。
引言
2022年年底OpenAI公司发布的ChatGPT突然以飞快的速度在全球同步发展,并且推出两个月月活用户突破1亿,成为了史上用户增长速度最快的消费级应用程序。但之后伴随而来的是,全球监管机构针对以ChatGPT为代表的生成式人工智能带来的数据安全、网络安全、个人信息保护、知识产权保护等各类风险的高度关注。意大利数据保护局(Garante per la Protezione dei Dati Personali)在今年3月底暂时禁用ChatGPT,并对该工具涉嫌违反隐私规则展开调查之后,美国、加拿大、英国、德国、法国、西班牙、日本等多个国家的监管机构均对生成式人工智能所带来的数据问题、知识产权问题等进行调查、发布相关指引或者表达了担忧。
在这样的背景下,2023年4月28日中共中央政治局召开会议强调,“要重视通用人工智能发展,营造创新生态,重视防范风险”。国家网信办4月11日公布的《生成式人工智能服务管理办法(征求意见稿)》(以下称“《征求意见稿》”),在经过三个月的酝酿与完善后,完成了国家互联网信息办公室审议,国家发展和改革委员会、教育部、科学技术部、工业和信息化部、公安部、国家广播电视总局七部委同意的立法进程,成为全球第一个全面监管生成式人工智能的立法文件,出台的《生成式人工智能服务管理暂行办法》(以下称“《暂行办法》”)于2023年7月13日公布,2023年8月15日起施行。
习近平总书记在《习近平总书记关于网络强国的重要思想概论》第五章“筑牢国家网络安全屏障”提到,“不发展是最大的不安全,绝不能因为安全问题而拒绝发展[1]。”《暂行办法》的出台,一方面,给出了我国针对AIGC快速发展的中国答案,贡献了中国智慧,是落实习近平总书记网络强国重要思想的生动体现,另一方面,《暂行办法》在治理思路上与之前已经生效的《互联网信息服务算法推荐管理规定》(以下称“《算法推荐管理规定》”)《互联网信息服务深度合成管理规定》(以下称“《深度合成管理规定》”)是一致的,但在治理制度方面,针对生成式人工智能技术提出了进一步明确的要求。本所将在《暂行办法》的监管原则之下,就其规定的具体治理制度进行梳理。
一、适用范围(第2条)
生成式人工智能在中国快速发展以来,什么样的是生成式人工智能产品/服务,如何使用生成式人工智能产品/服务,受到怎样的中国法律监管一直以来都是行业迫切关注的问题。为了反馈实践中的要求,以及促进行业发展,《暂行办法》相较之《征求意见稿》进一步明确以及限缩了适用范围:向中华人民共和国境内公众提供生成式人工智能服务。
但这其中需要特别强调如下词语的含义:
向中国境内:
在本条规定下,境内主体向境外提供人工智能服务的,无需适用《暂行办法》。但需要提醒注意的是,如果是中国境内的生成式人工智能服务在向境外提供服务过程中,即使不需要适用《暂行办法》,仍需要注意是否会产生数据出境等合规问题。
而境外主体向中国境内公众提供服务的,同样需要适用《暂行办法》。此外,《暂行办法》还在条文最后特别明确境外主体向中国境内提供服务应当符合外商投资相关规定。
面向公众:
“面向公众”的服务应当依据《暂行办法》依法治理,是由于人工智能生成物目前尚存在生成虚假信息(目前全球多个国家陆续发生ChatGPT生成的虚假信息导致的侵权或者犯罪案件)的风险,而进一步通过各种类型的“具有舆论与社会动员能力的服务”可能产生扩散效应,扰乱社会正常秩序发展,因此“面向公众”提供的服务,特别是针对“具有舆论属性或社会动员能力的服务”是监管的核心重点。
而“公众”通常应当被理解为“不特定多数”,因此当一项服务面向不特定多数时,无论其面向的是不特定多数的企业还是不特定多数的自然人,均构成“面向公众”。
另一方面,《暂行办法》规定,研发和应用生成式人工智能技术,只要未向境内公众提供服务的,就无需适用《暂行办法》,也就是如果仅在公司内部研发或者以提高办公效率之目的,公司内部使用则无需适用。这无疑为企业内部、垂直领域内的“面向非公众”的“研发、应用”(并非使用其提供服务)提供了宽松的监管空间。这与实践中大量企业存在使用生成式人工智能提升企业效率的需求相呼应,是《暂行办法》积极响应现实需求的体现。但同时需要注意,企业内部、垂直领域内的“面向非公众”的“研发、应用”即使无需适用《暂行办法》,但特别是在制作、发布、使用相关生成内容时,需要遵守包括《网络信息内容生态治理规定》在内的法律法规。
提供服务:
“提供服务”是与《算法推荐管理规定》《深度合成管理规定》中的“算法推荐服务”“深度合成服务”互相呼应,同时排除了进行“研发、应用”,进一步限缩风险较小的“面向非公众”的适用范围。
二、适用主体:生成式人工智能服务提供者(第22条(二))
在前述适用范围内适用《暂行办法》的主体,被明确规定为生成式人工智能服务提供者,是指利用生成式人工智能技术提供生成式人工智能服务(包括通过提供可编程接口等方式提供生成式人工智能服务)的组织、个人。需要强调的是《暂行办法》并未如《深度合成管理规定》一样,区分技术支持者和服务提供者,同时明确规定“通过可编程接口等方式提供服务“的主体同样适用《暂行办法》,例如2023年6月24日公布的已完成算法备案的技术支持者均是以API接口方式提供服务,因此可以看出《暂行办法》下技术支持者与服务提供者均受到同样的监管要求。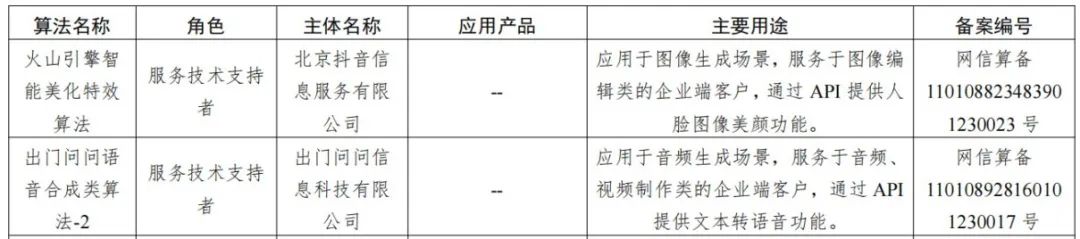
我们同样需要注意的是《暂行办法》目前的立法定位是“暂行”,并且仅有24条,仅规定了重大的监管原则以及目前亟待明确的事项,同时在泱泱众多的人工智能技术中生成式人工智能只是其中一种,因此2023年的立法计划中的《人工智能法》很有可能会进一步全面、完善地针对人工智能产业链上的不同主体提出不同的监管要求,这同样也是目前《暂行办法》中明确的“分类分级”监管原则的要求。
三、促进创新篇(第5条、第6条)
人工智能全产业链,包括从基础层的算力、芯片、训练数据到神经网络算法模型,向公众提供服务或产品的应用层,《暂行办法》均依据其不同的行业特点,制定不同的鼓励方向:
应用层:鼓励创新应用,生成积极健康的优质内容,构建应用生态体系;
技术层以及基础层:鼓励人工智能核心技术领域的自主创新,以及开展平等互利的国际交流与合作,参与国际标准制定;
基础层:推动基础设施和公共训练数据资源平台建设;促进算力资源协同共享,提升算力资源利用效能。推动公共数据分类分级有序开放,扩展高质量的公共训练数据资源。鼓励采用安全可信的芯片、软件、工具、算力和数据资源。
可以看出,《暂行办法》针对应用层重点鼓励生成积极健康的优质内容,而对技术层和基础层主要在促进加速基础设施(算力、数据等)建设以及鼓励平等的国际合作,参与国际标准制定。
四、依法治理篇
1、分类分级监管(第3条、第16条)
《暂行办法》在《征求意见稿》上增加确定了针对生成式人工智能包容审慎、分类分级的依法治理监管原则,这其实是延续了《中华人民共和国网络安全法》、《中华人民共和国数据安全法》中的分类分级规定,有利于生成式人工智能与相关法律的衔接。
落实到具体条款,《暂行办法》在“生成式人工智能服务提供者”的框架下区分出“具有舆论属性或者社会动员能力的生成式人工智能服务的”产品,并对其提出了更为严格的监管要求:应当按照国家有关规定开展安全评估。
另一个层面,“利用生成式人工智能服务从事新闻出版、影视制作、文艺创作等活动的”,未来将会由相关监管部门,包括国家互联网信息办公室、国家广播电视总局等相关主管部门另行规定,也可以看出是针对不同类型的生成式人工智能分类监管的体现。
但整体而言,《暂行办法》尚未建立如欧盟《人工智能法案》近似的分级监管体系(将所有人工智能产品/服务基于对人类健康安全等的影响区分为不可接受的风险、高风险、有限风险以及最低风险。其中前三类将受到法案的监管,第四种被称为“最小风险(包括例如具备AI功能的视频游戏或垃圾邮件过滤器等)”,根据欧盟委员会的说法,这一类别实际上涵盖了绝大多数人工智能系统。),一个重要的原因可能在于,立法者将这一任务留给了未来要制订的《人工智能法》完成,而针对众多人工智能服务/产品中的一类的生成式人工智能,目前仅采取如上分类分级措施。
2、监管治理重点:
针对人工智能技术特点的监管要求(第4条):
由于人工智能技术可以通过算法进行引导,如果训练数据、模型中存在歧视、偏见等有害信息,通过算法进行扩散输出将比通常的信息传播导致的不良影响更为严重,基于此《暂行办法》要求:
(1)坚持社会主义核心价值观,不得生成违法违规的内容;
(2)算法设计、训练数据选择、模型生成和优化、提供服务过程中应当采取防止算法歧视的措施;
(3)尊重知识产权、他人合法权益;
(4)提高生成式人工智能服务透明度,提高生成内容的准确性和可靠性。
针对不同的关键环节的监管要求(第7条、第8条、第14条):
数据训练阶段:提供者应当依法开展预训练、优化训练等训练数据处理活动:
(1)使用具有合法来源的数据和基础模型;
(2)涉及知识产权的,不得侵害他人依法享有的知识产权;
(3)涉及个人信息的,应当取得个人同意或者符合法律、行政法规规定的其他情形;
(4)采取有效措施提高训练数据质量,增强训练数据的真实性、准确性、客观性、多样性等;
(5)其他监管要求。
数据标注阶段:数据标注,提供者应当制定标注规则;开展数据标注质量评估,抽样核验标注内容的准确性;对标注人员进行必要培训,提升尊法守法意识,监督指导标注人员规范开展标注工作。
内容生成阶段:提供者应当在生成内容出现违法内容采取模型优化训练等措施进行整改。
需要注意的是,由于实践中生成式人工智能提供者的算法模型中包括大量第三方开源模型、数据库,特别是境外开源模型、数据库,因此如何认定“使用具有合法来源的数据和基础模型”将直接影响我国的生成式人工智能是否可以站在高个子身上向上发展。我们结合《暂行办法》第20条,境外向境内提供生成式人工智能服务不符合法律行政法规和本办法规定的,国家网信办部门应当进行处置,反之如果境外向境内提供的服务符合我国相关法律法规则可以被使用。因此,这提醒使用第三方开源模型、数据库的生成式人工智能提供者,应当在接入、使用三方开源模型、数据库时进行合规评估/内容审核等,保证使用是符合中国法律法规要求的。
其次,数据质量的提升也无疑是生成式人工智能服务提供者的难题,如何在庞大的训练数据中核实其数据的真实性、准确性、客观性,同时要保证多样性。这一难题通常可以通过确定数据来源的方式进行解决。
3、生成式人工智能服务提供者的服务规范:
衔接生成式人工智能服务提供者与其他法律主体之间的关系,明确其依据其他法律规定的法律责任(第9条):
(1)生成式人工智能服务提供者承担网络信息内容生产者的法律责任,应当遵守《网络信息内容生态治理规定》第二章的规定;
(2)涉及个人信息的,生成式人工智能服务提供者承担个人信息处理者责任,应当遵守《个人信息保护法》中赋予个人信息处理者的法律责任;
(3)生成式人工智能服务提供者应当与其用户/客户签订服务协议,依据《民法典》明确双方权利义务。
保护未成年人(第10条)
生成式人工智能的使用将大幅降低学生通过自己的努力获取知识,而仅凭询问人工智能即可轻易获得作业答案,甚至论文,这无疑已经使很多人开始担忧未成年人的教育问题。日本文部省(教育部)就今年6月22日公布了一项指导法案,允许在小学、初中和高中有限度地使用ChatGPT类生成式人工智能,但也明确规定限制措施,例如小学生(13 岁以下)使用AI时需要特别谨慎。而任何由AI生成的作业,一经判定,将被视为作弊。
而《暂行办法》也同样规定生成式人工智能服务提供者应当采取有效措施防范未成年人用户过度依赖或者沉迷服务。但与日本文部省做法的区别在于,中国监管部门将这一责任负之于服务提供者,要求其采取有效措施防沉迷或者过度依赖,而日本是通过劝告学生、家长以及学校的方式避免未成年人在学习中过度使用。
对Prompt的保护、生成内容的标识(第11条、第12条)
针对用户使用生成式人工智能服务过程中,需要向服务者发送Prompt才可以获得其反馈的信息,而发送的Prompt中经常会包括使用者的个人信息,因此《暂行办法》明确要求生成式人工智能服务提供者应当对Prompt进行保护,并且对使用者发送的Prompt中的个人信息的收集应当符合《个人信息保护法》的规定。
另一方面,《暂行办法》衔接《深度合成管理规定》,要求提供者对图片、视频等生成内容进行标识。这里需要注意的是,《深度合成管理规定》所规定的标识包括两种类型:
(1)深度合成服务提供者对使用其服务生成或者编辑的信息内容,应当采取技术措施添加不影响用户使用的标识。这里是指在生成内容中添加隐式标识。
(2)在生成或者编辑的信息内容的合理位置、区域进行显著标识,向公众提示深度合成情况。这里是指在提供服务时,在相关位置或者区域提示告知用户深度合成情况。
而《暂行办法》关注的明显是前者。隐式标识的强制要求加入,无疑可以对利用人工智能进行违法犯罪的活动进行充分举证,以及可以防止人们被不良分子使用人工智能生成内容诈骗等。
生成违法内容的处置、预防措施(第14条、第15条)
生成式人工智能服务提供者在发现其服务生成违法内容时,应当采取停止生成、停止传输、消除等处置措施,采取模型优化训练等措施进行整改,并向有关主管部门报告。
在4月11日发布的《征求意见稿》中,网信办尚采取要求服务提供者发现违法生成内容后3个月内对算法进行整改防止再次生成违法内容的方式,但《暂行办法》已经修改为更为柔和的“采取模型优化训练等措施进行整改”,删除了3个月的时间限制,也删除了“防止再次发生”的结果限制,大大加强了该条款的可落地性。
但即使在目前的条款下,生成式人工智能服务提供者仍需要建立一套完整的处置、预防措施,包括发现不同的违法内容应当采取不同的处置机制。
在处置机制的前提下,《暂行办法》也要求服务提供者建立健全投诉举报机制。
4、监督手段:
安全评估与算法备案(第17条)
《暂行办法》第17条规定,“提供具有舆论属性或者社会动员能力的生成式人工智能服务的,应当按照国家有关规定开展安全评估,并按照《互联网信息服务算法推荐管理规定》履行算法备案和变更、注销备案手续”。其保留了《征求意见稿》中的安全评估与算法备案的要求,但其完成时间修订为“按照国家有关规定开展”,不再强行要求两者均在服务上线前完成。
但需要注意的是,与4月11日公布的《征求意见稿》相比,《暂行办法》删除了安全评估“依据《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》”的内容,因此目前安全评估的具体实施细则尚不明确,虽然部分省份网信办已经开展相关安全评估工作,但相关明确的指引尚需等待监管部门明确的意见。
另一方面,算法备案则继续按照《深度合成管理规定》的要求,提供服务之日起十个工作日内完成相关算法备案手续。因此相关企业应当尽快评估是否需要完成算法备案工作手续,以及具体备案角色(服务提供者或者技术提供者)。
附件:《生成式人工智能服务管理暂行办法》与征求意见稿对比版




[1]《习近平总书记关于网络强国的重要思想概论》,中央网络安全和信息化委员会办公室,人民出版社2023年7月,P91
全球首部AIGC立法发布:贡献治理AIGC的中国智慧(附完整对比稿)
作者:时萧楠 王艺来源:北京植德律师事务所

观点摘要 01、在经过三个月的酝酿与完善后,完成了国家互联网信息办公室审议,国家发展和改革委员会、教育部、科学技术部、工业和信息化部、公安部、国家广播电视总局七部委同意的立法进程,《生成式人工智能服务