
三、《暂行办法》与其他法律的衔接
《暂行办法》作为AIGC服务领域的行政规章, 其很多制度的落实和执行依赖于相关法律和行政法规。
1. 生成式人工智能兴起所引发的知识产权保护与争议
《暂行办法》要求训练数据不侵犯知识产权, 而判断是否侵犯知识产权则依赖于具体的相关《著作权法》规定和其它知识产权有关法律。
AI技术有关的知识产权争议, 主要集中于以下三点: (1) AIGC权属问题; (2) 模型训练的侵权风险; 以及(3) AIGC的侵权风险。我们在《风起云涌的AIGC:监管、知识产权与算法安全——中篇:AIGC之知识产权》二. AIGC作品的权属中已经对上述(1)的问题试进行过探讨, 本文主要考虑AIGC与模型训练以及与用户互动中可能存在的侵权风险与保护思路。
(1) 模型训练行为
《暂行办法》第7条明确规定, “提供者应当依法开展预训练、优化训练等训练数据处理活动, 涉及知识产权的, 不得侵犯他人依法享有的知识产权。”算法模型训练需要庞大的数据库做支持, 训练素材一般来自于公开互联网, 不可回避地包括到著作权保护的作品(“作品”)。从模型训练行为本身的目的考虑, 这种使用需涵盖作品的实质内容或几乎所有内容, 极易存在侵犯作品复制与修改权的风险。
模型训练行为所引发的著作权纠纷在域外已有实例。今年1月, 有作者向利用扩散模型等算法进行图片生成的公司Stability AI, LTD,等提起集体诉讼(“Stability案”), 指控其 “未经作者同意, 使用作品以进行机器学习、人工智能等….的训练”[7]。类似地, 上月7号Sarah Silverman等人也对OpenAI, INC.等提起著作权等侵权之诉(“OpenAI案”), 认为OpenAI公司 “在语言模型训练中未经原告同意复制了原告的作品, 且由于OpenAI的语言模型的运作不能缺少其模型中留存的、从他人作品中提取出的信息表达部分, OpenAI模型构成侵权的衍生作品”。[8]
在一些场合, 模型训练中对素材的使用可能被视为合理使用。在我国现行的《著作权法》中, 被诉侵权行为, 如符合《著作权法》第24条的合理使用情形, 同时不影响作品的正常使用, 且没有不合理地损害著作权人的合法权益的, 属于法律允许的合理使用行为。就模型训练行为而言, 似乎可以从“合理使用”角度考虑。
模型训练似乎类似于《著作权法》第24条下“学习使用”, 即“为个人学习、研究或者欣赏, 使用他人已经发表的作品”。但是, 此处的个人指的是“自然人”, 而非“人工智能”, 机器的学习虽然在概念上相应于个人学习, 但在法律含以上与之不同。
那么, 模型训练行为是否属于《著作权法》第24条下的“适当引用”?一般而言, “适当引用”仅允许引用部分作品内容以评价作品, 或说明其他问题。在模型训练行为中, AIGC服务提供者可以主张, 模型训练所使用作品, 仅只为了让模型更了解人类语言、绘画或其他作品创作中的模式, 比起对作品进行“引用”和“替代”的, 算法模型更多是对相应的作品进行编码与训练。例如, 利用扩散模型进行图片生成时, 其原理主要包含正向扩散与逆向扩散, 在对原始输入图片解码后, 使用马尔卡夫链模型, 计算原始输入图片到纯高斯噪声状态变化的概率分布, 并让机器通过计算逆推正向扩散的反过程, 重现图片。
AIGC服务提供者利用“适当引用”的主要不足之处在于: 模型训练行为使用与转化的图片是海量的, 引用占比极大, 且难以剔除其商业目的与属性。但另一方面, 模型训练行为确与一般的侵权行为不同, 其服务于机器算法, 不是《著作权法》意义上典型的作品复制与传播行为; 同时, 模型训练行为未必影响到了原作者的利益, 甚至不会触及原作品的流通与传播渠道, 特别是对于图像等内容来说, 训练前提就是将其转化为编码语言, 这种使用似乎并不会削弱原作品在原有流通渠道中所强调的艺术价值。
另一种意见认为, 训练中的使用属于“转化性使用”。“转化性使用”并非是我国著作权的概念, 是在美国1994年最高院的判例Campbell v. Acuff-Rose Music.中的确立的一种合理使用情形。其通过合理使用的四要件分析[9], 认为在判断某一作品使用行为是否属于合理使用的, 应考虑其使用性质, 如果其没有重复原作品, 而赋予了原作品新的价值属性的, 不属于侵权。“转化性使用”能被豁免的原因在于, 作品的新旧价值互不干扰, 均能鼓励推动创新。而我国最高院在2011年发布的《关于充分发挥知识产权审判职能作用推动社会主义文化大发展大繁荣和促进经济自主协调发展若干问题的意见》(“《若干意见》”)中也提到, “在促进技术创新和商业发展确有必要的特殊情形下, 考虑作品使用行为的性质和目的、被使用作品的性质、被使用部分的数量和质量、使用对作品潜在市场或价值的影响等因素, 如果该使用行为既不与作品的正常使用相冲突, 也不至于不合理地损害作者的正当利益, 可以认定为合理使用。”《若干意见》中提出可考虑的四个合理使用因素, 恰好是美国法律下合理使用四要件的判断要素。
近年来, 我们也发现, 已经有部分企业在著作权纠纷的案件中提出了“转化性使用”作为支持合理使用的辩护意见[10]。而在(2015)沪知民终字第730号中, 一审法院使用了四要件的标准得出合理使用的结论, 也被终审法院支持。综上, 虽我国暂未确定“转化性使用”这一合理使用概念, 但考虑到《若干意见》以及部分司法实务的现状, 了解美国法下 “转化性使用”在人工智能领域的应用对AIGC服务提供者有很高的实践帮助价值。
早在OpenAI案前, USPTO在2019年就人工智能创新的知识产权保护问题向公众征求意见[11]。其中问题3是“AI算法或处理通过吸收大量受保护的作品以完成训练与进化, 是否有任何现存的法律理论或案例可以支持这种使用的合法性?”OpenAI, LP (同样是OpenAI案的被告之一)起草了回复, 认为模型训练行为应属于“转化性使用”[12]。其理由在于:
(1) 使用性质: 模型训练行为的使用性质具有高度的转化性。原始作品提供的是独立的娱乐价值, 而模型处理行为是为了训练。没有人可以通过研究AI系统和AI输出内容的形式获取原始作品 。在高转化性的使用行为下, 公司是否盈利、是否有商业目的也不会决定性影响前述判断。
(2) 使用部分: 模型训练行为几乎使用了原作品的所有部分, 但这种使用并不被公众可及, 不会替代原作品的使用。且完整使用对模型训练行为本身是必要的, 这决定了模型训练后的完整度和实用性。
(3) 使用影响: 模型训练行为不会影响原作品的市场, 语料库受众对象是机器, 而非人类, 语料库使用原作品并不会导致原作者的受众减少。
值得关注的是, 今年1月的Stability案已经有了一些进展。在4月18日被告提出的撤诉申请(motion to dismiss)中, 被告在前置性说明内强调, Stable Diffusion复制与记忆图片并不是为了分发, 而是为了对图画中的数百万个参数进行开发完善。[14]模型训练行为是否属于合理使用或是侵权行为, 希望Stability案以及OpenAI案能给我们一个答案。
(2) AIGC的侵权风险
除了模型训练行为以外, AIGC服务的合法性与使用者更为相关。输出内容是否可能因为与受保护的作品“实质性相似”+“存在接触可能性”而被认为构成著作权侵权。如果构成的, 谁才是侵权人?AIGC服务使用者还是提供方?
《暂行办法》并没有明确说明AIGC知识产权侵权的问题, 但强调了服务提供者应当承担网络信息内容生产者的责任(第9条)。在《网络信息内容生态治理规定》规定下, 网络信息内容生产者不得损害他人合法权益。网络信息内容的生产者, 不得制作、复制、发布违法信息, 还需要采取措施抵制违法行为与违法内容。可以认为, 知识产权应作为考虑因素。
从著作权侵权角度而论, AIGC服务提供者需有效避免AIGC“实质性相似”以及“存在接触可能性”的可能。“接触可能性”对AIGC服务提供者而言一般难以回避, 毕竟模型训练涉及数量范围很广。但有趣地是, 正因为AIGC“集百家所长”, 其与单个作品的表达之间的相似程度被极大削弱。AIGC服务提供者也许可以宣称, AIGC更倾向于“风格相似”而非“表达相似”的新的作品。
Stability案中, 原告也在起诉状中承认“插入多种图像后…, …被告软件中基于特定指令输出的图片与任何素材数据都无法高度匹配。”[15]这段话也在被告的撤诉申请中屡遭引用作为抗辩。在AI技术不断发展的今天, AI技术提供者也可以对模型与算法本身进行限制, 从而进一步降低其输出数据与训练数据之间的相似程度, 从而规避侵权风险。
2. 生成式人工智能的个人信息保护问题
如何最大发挥个人信息的经济效益并平衡个人权益保护, 对任何AIGC服务提供者来说都是难题。早在今年4月份, 路透社爆出意大利个人数据保护局宣布禁止使用ChatGPT, 因其涉嫌违法收集小于13岁的儿童的个人信息。目前, ChatGPT在意大利地区已经恢复使用, 但在进入聊天界面前设置了弹窗, 用户必须确认其已满18岁, 或已满13岁且获得父母/监护人的同意。就在不久前的7月13日, 美国联邦贸易委员会召开听证会, 对OpenAI公司存在的隐私安全、消费者权益相关的潜在风险进行调查。
本次出台的《暂行办法》强调了AIGC服务提供者的个人信息保护义务, 并与《个人信息保护法》实现联动。重点个人信息保护义务如下:
(1) 模型训练阶段, 收集个人信息应当具备合法基础并符合其他法律要求(第7条)
本条对应《个人信息保护法》第13条等的义务, 即要求AIGC服务提供者确保模型训练时使用的个人信息均具有合法基础。
如上所述, AIGC服务语料库的训练数据一般来自于公开互联网, 且数据量庞大。追溯所有个人信息主体并取得他们的个人同意几乎没有可能。对于AIGC服务提供者而言, 能否可以援引《个人信息保护法》第13条(四)“在合理的范围内处理个人自行公开或者其他已经合法公开的个人信息; ”作为处理个人信息的合法基础便成为了关键。该合法基础需要关注信息公开的方式, 以及拟进行的处理的性质。
一方面, 对公有领域个人信息进行使用, 必须需要限于“合理的范围内”还不得“对个人权益产生重大影响”(第27条), 否则需要重新获得个人的同意。模型训练行为是否属于“对个人权益产生重大影响”、超出合理范围的处理行为?AIGC服务提供者可以主张, 模型训练行为本身并不针对任何个体, 训练过程打破了个人信息的个体颗粒度, 反倒不会体现某一个体的特征, 对个人权益产生的影响也较小。换言之, 这也促使AIGC服务提供者尽可能减少模型训练行为对个人权益的影响, 例如尽可能减少对原始数据的留存与重现, 对训练数据进行必要的去标识化或匿名化处理等, 否则AIGC服务提供者只能退而求其次, 诉诸高成本的“知情同意”合法基础。
另一方面, 处理个人信息需要履行告知义务。在难以触达所有用户的公开互联网中, 公告似乎是AIGC服务提供者能够选择的最可行方式, 但公告方式, 严格意义上而言不一定能覆盖所有相关个人, 其效果也存在不确定性。且值得注意的是, 《个人信息保护法》中并没有基于告知难度过高, 成本过大显不合理而豁免个人信息处理者告知义务的例外。
(2) 服务阶段, 收集使用个人信息应遵守个人信息保护义务(第9条)
在AIGC服务阶段, 个人信息保护义务主要有以下几个方面:
a) 知情同意(第9、11条)
AIGC服务过程中收集、对外提供用户个人信息的, 应当提供个人信息处理说明并获得用户同意(或满足其他的合法基础)。
b) 最小必要(第11条)
《暂行办法》要求AIGC服务提供者不得收集非必要个人信息。这可能涉及到服务注册登录阶段以及实际使用阶段, AIGC服务提供者收集的个人信息需与其所声明的且实际使用的业务场景相适应。
此外, 《暂行办法》对于输入信息、使用记录的留存时间进行了明确规定。要求AIGC服务提供者不得非法留存能够识别使用者身份的输入信息和使用记录。笔者推测, 《暂行办法》可能考虑到了AIGC服务提供者留存使用者的使用记录并进一步进行用户画像或进行其他模型训练的风险。当然, 这一条并非禁止AIGC服务提供者留存任何个人信息, 而是强调留存的合法前提在于: 用户没有主动要求撤回同意或删除相关信息, 且个人信息留存后具有与之适应的处理目的与业务场景。
c) 权利响应(第11条)
《暂行办法》对个人信息权利进行了重述, 即提供者应当提供及时、便捷有效的响应渠道以响应个人对个人信息的查询、复制、更正、补充、删除等个人信息权利的请求。
前述个人信息保护义务并非《暂行办法》首创, 而是《个人信息保护法》下的规定在AIGC服务领域的重述。但是, 如何在AIGC服务场景中落实个人信息保护的相关规定, 比如就用户向AIGC提供的个人信息, 如何回应用户的查询、复制等请求, 则还是一个有待实践的问题。
3. AIGC服务中的算法服务相关要求
几年来已通过了数部与算法相关的管理规定。从范围较广的“算法服务”, 到“深度合成类的算法服务”, 再到本文聚焦的“AIGC服务”, 有关算法立法在不断精细化。AIGC服务不但需要满足《暂行办法》下的特殊规定, 还必须遵守与算法服务相关的一般规定。
首先, 对于算法的披露义务。参见本文第四部分第2节有关算法透明度、准确性和可靠性要求的介绍。
其次, 对于算法的安全评估和备案义务。《暂行办法》延续了《互联网信息服务算法推荐管理规定》《互联网信息服务深度合成管理规定》中对于安全评估与备案义务的规定。也就是说, AIGC服务与其上位概念深度合成类服务, 算法推荐服务一致, 提供具有舆论属性或者社会动员能力的信息服务的进行备案。有趣地是, 作为备案前提, “舆论属性”“社会动员能力”的定义却并不明确。根据《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》下的定义, 开办论坛、博客、微博客、聊天室、通讯群组、公众账号、短视频、网络直播、信息分享、小程序等信息服务或者附设相应功能的, 均可以视为具有“舆论属性或社会动员能力”。一般认为, 渠道特征是重要的考量因素——即使受众很少, 但一旦渠道是较为公开的且面对不特定用户的, 都不能排除具有“舆论属性或社会动员能力”的可能。
算法备案监管已经提上日程, AIGC服务提供者可以趁《暂行办法》生效前夕进一步向监管征询了解备案问题。截止8月份, 网信办已经发表了4份算法备案清单(http://www.cac.gov.cn/2022-08/12/c_1661927474338504.htm), 以及一份深度合称服务备案清单(http://www.cac.gov.cn/2023-06/20/c_1688910683316256.htm)。已经备案的服务提供者、技术支持者基本仍限于主流的互联网信息服务公司。
最后, 对于生成内容的标识义务。《暂行办法》要求提供者按照《互联网信息服务深度合成管理规定》对图片、视频等生成内容进行标识。目前对标识的要去主要限于两类。一类是《互联网信息服务深度合称管理规定》第17条中所列举的可能导致公众混淆或者误认的生成内容。至于不落入前述条款的生成内容, 提供者不需要进行显著标识, 但应当提供给使用者标识功能以供其选择使用。
四、《暂行办法》下的热点问题
对于AIGC服务中经常被关注的问题, 《暂行办法》或多或少给予了回应。
1. 数据来源的合法性要求和判断
人工智能依赖三大要素, 即: 数据、算法和算力, 而数据则是人工智能研究和发展的基石。为训练出更加准确、可靠的模型, 需要大规模、高质量的数据作为养分, 以进行数据的分析、预测和决策。《暂行办法》第7条对AIGC服务提供者在开展预训练、优化训练过程中, 数据及基础模型的合法性进行了规制, 其要求数据来源必须合法, 不得侵害他人依法享有的知识产权及个人信息权益等。
训练模型的数据主要来源于公开数据、自有数据以及第三方数据。对于不同来源及类型的数据合法性判断, 所依据的法律及合规措施不尽相同, 例如, 在生成式人工智能的训练数据中, 企业可能使用了通过爬虫技术爬取的公开数据, 对于这些数据的使用是否合法, 则需要具体结合《反垄断法》以及《反不正当竞争法》等法律法规以及目前司法实践的相关要求, 避免对原始数据的权利人或平台数据的开发者造成侵权或其他权益上的损害; 又如, 训练数据中可能包含了他人的个人信息, 对于该等数据的收集及使用, 则应当遵守上位法《个人信息保护法》中有关获得个人信息主体的知情同意或其合法基础的相关规定; 再如, 若企业使用了未经许可他人享有著作权的作品进行数据训练, 是否构成《著作权法》规定的“合理使用”范围则值得商榷, 正如我们上文所提到的, 合理使用认定的过程往往很复杂, 且因具体情况而定, 特别对于AI技术这样的新兴行业, 短时间内无论是司法、执法机关亦或是AIGC服务提供者, 都仍在探索把握。由此则可能具有侵犯他人合法知识产权的风险, 企业应当注意规避相关风险。
2. 算法透明度、准确性和可靠性要求
算法透明是人工智能治理领域公认的原则, 其要求算法所有者对算法的机制、决策过程等进行披露和公示, 旨在保护公众的知情权。我国在《关于加强互联网信息服务算法综合治理的指导意见》中, 也强调了算法应用应当透明可释的原则, 在《互联网信息服务算法推荐管理规定》、《互联网信息服务深度合成管理规定》等规范中亦明确了算法备案、安全评估等监管和问责的手段。
相比于《征求意见稿》, 《暂行办法》删除了其17条对生成式人工智能提供者“提供可以影响用户信任、选择的必要信息”以及“人工标注数据的规模和类型, 基础算法和技术体系等”, 而是要求提升AIGC服务的透明度(第4条第5项)以及对算法机理等予以说明(第19条)。由此变化可以看出《暂行办法》相对降低了对AIGC服务提供者在算法透明度上的要求。其一, 实现算法完全透明存在技术上的难度, 即机器学习法存在“算法黑箱”, 算法的推演不完全依照人类逻辑, 会导致部分算法无法被完全解释; 其二, 算法通常属于企业的核心竞争力, 可能构成商业秘密或知识产权, 过分的公开披露企业算法的运作机制将可能破坏企业的市场竞争力, 影响企业的发展动力。尤其可见, 《暂行办法》相较于征求意见稿平衡了公众知情权与企业商业秘密、知识产权保护之间的关系。
同样, 相对于《征求意见稿》, 《暂行办法》适当降低了对训练数据质量的要求。《征求意见稿》第7条中要求“能够保证数据的真实性、准确性、客观性、多样性”, 但事实上, 要求训练的数据完全符合真实性、可靠性等要求, 对于服务提供者而言往往难以保证。首先, 由于加入模型训练的数据很多都源于公开领域, 而该部分数据可能良莠不齐, 不可避免会有事实性的错误或虚假内容等。其次, 即使数据准确, 也未必客观, 数据本身可能存在社会性的偏差和误解。
《暂行办法》将《征求意见稿》修订为“采取有效措施, 提供训练数据质量、增强训练数据的真实性、准确性、客观性、多样显示器设置专注性”, 则是更加符合AIGC服务领域的现实, 强调在数据训练过程中行为方式和主管因素。《暂行办法》适度放宽了生成式人工智能数据训练方面的具体合规要求, 从一定程度上减轻了服务提供者的相应责任, 也是更多的从实际的角度进行了考量。
3. 生成内容的责任
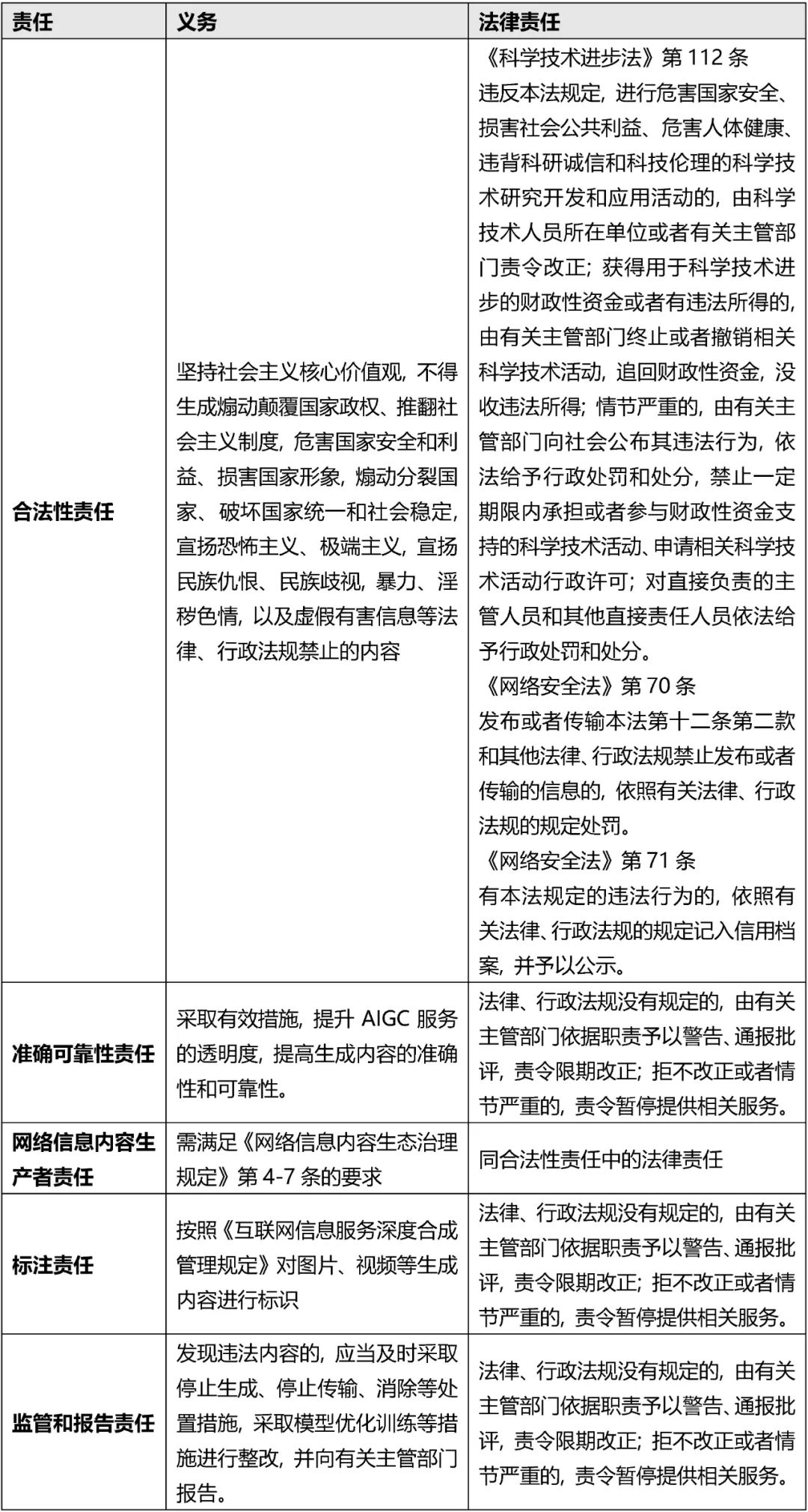
服务提供者需要对生成式人工智能生成的内容负有一定的责任。根据《暂行办法》第21条, “提供者违反本办法规定的, 由有关主管部门依照《中华人民共和国网络安全法》、《中华人民共和国数据安全法》、《中华人民共和国个人信息保护法》、《中华人民共和国科学技术进步法》等法律、行政法规的规定予以处罚; 法律、行政法规没有规定的, 由有关主管部门依据职责予以警告、通报批评, 责令限期改正; 拒不改正或者情节严重的, 责令暂停提供相关服务。”如下, 我们整理了服务提供者对人工智能生成的内容负有的义务及需要承担的法律责任。
五、结语
《暂行办法》在吸收有关部门、行业和公众对《征求意见稿》的意见和建议的基础上, 更加充分考虑了AIGC服务的技术特点和难点, 体现了国家坚持发展与安全并重, 在鼓励创新、支持新兴AI 服务领域发展的同时, 采取包容审慎的原则, 明确了AI 服务领域的安全底线, 同时也为AIGC服务企业的发展预留了的空间。这是我国对AIGC服务领域立法的一次积极探索, 未来可以预见, 将会有更加全面的监管治理体系形成。
对于提供AIGC服务的企业而言, 则需要在开展科技创新的同时, 提高自身的合规意识, 在数据的开发使用、用户权益保护以及生成内容的准确性、透明性等方面按照《暂行办法》的指引建立良好的合规体系。
注:
[7] Andersen et al v Stability Al Ltd. et Compliant ¶155“Defendants had access to but were not licensed by Plaintiffs or the Class to train any machine learning, AI, or other computer program, algorithm, or other functional prediction engine using the Works”
[8] Silverman Et Al V. Openai, Inc. Et Al ¶56-57 “OpenAI made copies of Plaintiffs’ books during the training process of the OpenAI Language Models without Plaintiffs’ permission, …Because the OpenAI Language Models cannot function without the expressive information extracted from Plaintiffs’ works (and others) and retained inside them, the OpenAI Language Models are themselves infringing derivative works…”
[9] 使用目的与特点、被使用作品的性质、被使用部分的比例与实质性、对市场或原作品的价值的影响。
[10] (2021)京0102民初37702号、(2019)粤03民初2836号等
[11] 《RequestforCommentsonIntellectualPropertyProtectionforArtificialIntelligenceInnovation》https://www.uspto.gov/sites/default/files/documents/OpenAI_RFC-84-FR-58141.pdf
[12] 《Comment Regarding RequestforCommentsonIntellectualPropertyProtectionforArtificialIntelligenceInnovation Docket No. PTO–C–2019–0038 Comment of Open AI, LP Addressing Question 3》
[13] “nobody looking to read a specific webpage contained in the corpus used to train an AI system can do so by studying the AI system or its outputs.”
[14] Andersen et al v Stability Al Ltd. et, Amended Motion to Dismiss, ¶2 “To be clear, training a model does not mean copying or memorizing images for later distribution. Indeed, Stable Diffusion does not “store” any images. Rather, training involves development and refinement of millions of parameters that collectively define—in a learned sense—what things look like. Lines, colors, shades, and other attributes associated with innumerable subjects and concepts.”
[15] Andersen et al v Stability Al Ltd. et Compliant ¶93 “none of the Stable Diffusion output images provided in response to a particular Text Pr
《暂行办法》作为AIGC服务领域的行政规章, 其很多制度的落实和执行依赖于相关法律和行政法规。
1. 生成式人工智能兴起所引发的知识产权保护与争议
《暂行办法》要求训练数据不侵犯知识产权, 而判断是否侵犯知识产权则依赖于具体的相关《著作权法》规定和其它知识产权有关法律。
AI技术有关的知识产权争议, 主要集中于以下三点: (1) AIGC权属问题; (2) 模型训练的侵权风险; 以及(3) AIGC的侵权风险。我们在《风起云涌的AIGC:监管、知识产权与算法安全——中篇:AIGC之知识产权》二. AIGC作品的权属中已经对上述(1)的问题试进行过探讨, 本文主要考虑AIGC与模型训练以及与用户互动中可能存在的侵权风险与保护思路。
(1) 模型训练行为
《暂行办法》第7条明确规定, “提供者应当依法开展预训练、优化训练等训练数据处理活动, 涉及知识产权的, 不得侵犯他人依法享有的知识产权。”算法模型训练需要庞大的数据库做支持, 训练素材一般来自于公开互联网, 不可回避地包括到著作权保护的作品(“作品”)。从模型训练行为本身的目的考虑, 这种使用需涵盖作品的实质内容或几乎所有内容, 极易存在侵犯作品复制与修改权的风险。
模型训练行为所引发的著作权纠纷在域外已有实例。今年1月, 有作者向利用扩散模型等算法进行图片生成的公司Stability AI, LTD,等提起集体诉讼(“Stability案”), 指控其 “未经作者同意, 使用作品以进行机器学习、人工智能等….的训练”[7]。类似地, 上月7号Sarah Silverman等人也对OpenAI, INC.等提起著作权等侵权之诉(“OpenAI案”), 认为OpenAI公司 “在语言模型训练中未经原告同意复制了原告的作品, 且由于OpenAI的语言模型的运作不能缺少其模型中留存的、从他人作品中提取出的信息表达部分, OpenAI模型构成侵权的衍生作品”。[8]
在一些场合, 模型训练中对素材的使用可能被视为合理使用。在我国现行的《著作权法》中, 被诉侵权行为, 如符合《著作权法》第24条的合理使用情形, 同时不影响作品的正常使用, 且没有不合理地损害著作权人的合法权益的, 属于法律允许的合理使用行为。就模型训练行为而言, 似乎可以从“合理使用”角度考虑。
模型训练似乎类似于《著作权法》第24条下“学习使用”, 即“为个人学习、研究或者欣赏, 使用他人已经发表的作品”。但是, 此处的个人指的是“自然人”, 而非“人工智能”, 机器的学习虽然在概念上相应于个人学习, 但在法律含以上与之不同。
那么, 模型训练行为是否属于《著作权法》第24条下的“适当引用”?一般而言, “适当引用”仅允许引用部分作品内容以评价作品, 或说明其他问题。在模型训练行为中, AIGC服务提供者可以主张, 模型训练所使用作品, 仅只为了让模型更了解人类语言、绘画或其他作品创作中的模式, 比起对作品进行“引用”和“替代”的, 算法模型更多是对相应的作品进行编码与训练。例如, 利用扩散模型进行图片生成时, 其原理主要包含正向扩散与逆向扩散, 在对原始输入图片解码后, 使用马尔卡夫链模型, 计算原始输入图片到纯高斯噪声状态变化的概率分布, 并让机器通过计算逆推正向扩散的反过程, 重现图片。
AIGC服务提供者利用“适当引用”的主要不足之处在于: 模型训练行为使用与转化的图片是海量的, 引用占比极大, 且难以剔除其商业目的与属性。但另一方面, 模型训练行为确与一般的侵权行为不同, 其服务于机器算法, 不是《著作权法》意义上典型的作品复制与传播行为; 同时, 模型训练行为未必影响到了原作者的利益, 甚至不会触及原作品的流通与传播渠道, 特别是对于图像等内容来说, 训练前提就是将其转化为编码语言, 这种使用似乎并不会削弱原作品在原有流通渠道中所强调的艺术价值。
另一种意见认为, 训练中的使用属于“转化性使用”。“转化性使用”并非是我国著作权的概念, 是在美国1994年最高院的判例Campbell v. Acuff-Rose Music.中的确立的一种合理使用情形。其通过合理使用的四要件分析[9], 认为在判断某一作品使用行为是否属于合理使用的, 应考虑其使用性质, 如果其没有重复原作品, 而赋予了原作品新的价值属性的, 不属于侵权。“转化性使用”能被豁免的原因在于, 作品的新旧价值互不干扰, 均能鼓励推动创新。而我国最高院在2011年发布的《关于充分发挥知识产权审判职能作用推动社会主义文化大发展大繁荣和促进经济自主协调发展若干问题的意见》(“《若干意见》”)中也提到, “在促进技术创新和商业发展确有必要的特殊情形下, 考虑作品使用行为的性质和目的、被使用作品的性质、被使用部分的数量和质量、使用对作品潜在市场或价值的影响等因素, 如果该使用行为既不与作品的正常使用相冲突, 也不至于不合理地损害作者的正当利益, 可以认定为合理使用。”《若干意见》中提出可考虑的四个合理使用因素, 恰好是美国法律下合理使用四要件的判断要素。
近年来, 我们也发现, 已经有部分企业在著作权纠纷的案件中提出了“转化性使用”作为支持合理使用的辩护意见[10]。而在(2015)沪知民终字第730号中, 一审法院使用了四要件的标准得出合理使用的结论, 也被终审法院支持。综上, 虽我国暂未确定“转化性使用”这一合理使用概念, 但考虑到《若干意见》以及部分司法实务的现状, 了解美国法下 “转化性使用”在人工智能领域的应用对AIGC服务提供者有很高的实践帮助价值。
早在OpenAI案前, USPTO在2019年就人工智能创新的知识产权保护问题向公众征求意见[11]。其中问题3是“AI算法或处理通过吸收大量受保护的作品以完成训练与进化, 是否有任何现存的法律理论或案例可以支持这种使用的合法性?”OpenAI, LP (同样是OpenAI案的被告之一)起草了回复, 认为模型训练行为应属于“转化性使用”[12]。其理由在于:
(1) 使用性质: 模型训练行为的使用性质具有高度的转化性。原始作品提供的是独立的娱乐价值, 而模型处理行为是为了训练。没有人可以通过研究AI系统和AI输出内容的形式获取原始作品 。在高转化性的使用行为下, 公司是否盈利、是否有商业目的也不会决定性影响前述判断。
(2) 使用部分: 模型训练行为几乎使用了原作品的所有部分, 但这种使用并不被公众可及, 不会替代原作品的使用。且完整使用对模型训练行为本身是必要的, 这决定了模型训练后的完整度和实用性。
(3) 使用影响: 模型训练行为不会影响原作品的市场, 语料库受众对象是机器, 而非人类, 语料库使用原作品并不会导致原作者的受众减少。
值得关注的是, 今年1月的Stability案已经有了一些进展。在4月18日被告提出的撤诉申请(motion to dismiss)中, 被告在前置性说明内强调, Stable Diffusion复制与记忆图片并不是为了分发, 而是为了对图画中的数百万个参数进行开发完善。[14]模型训练行为是否属于合理使用或是侵权行为, 希望Stability案以及OpenAI案能给我们一个答案。
(2) AIGC的侵权风险
除了模型训练行为以外, AIGC服务的合法性与使用者更为相关。输出内容是否可能因为与受保护的作品“实质性相似”+“存在接触可能性”而被认为构成著作权侵权。如果构成的, 谁才是侵权人?AIGC服务使用者还是提供方?
《暂行办法》并没有明确说明AIGC知识产权侵权的问题, 但强调了服务提供者应当承担网络信息内容生产者的责任(第9条)。在《网络信息内容生态治理规定》规定下, 网络信息内容生产者不得损害他人合法权益。网络信息内容的生产者, 不得制作、复制、发布违法信息, 还需要采取措施抵制违法行为与违法内容。可以认为, 知识产权应作为考虑因素。
从著作权侵权角度而论, AIGC服务提供者需有效避免AIGC“实质性相似”以及“存在接触可能性”的可能。“接触可能性”对AIGC服务提供者而言一般难以回避, 毕竟模型训练涉及数量范围很广。但有趣地是, 正因为AIGC“集百家所长”, 其与单个作品的表达之间的相似程度被极大削弱。AIGC服务提供者也许可以宣称, AIGC更倾向于“风格相似”而非“表达相似”的新的作品。
Stability案中, 原告也在起诉状中承认“插入多种图像后…, …被告软件中基于特定指令输出的图片与任何素材数据都无法高度匹配。”[15]这段话也在被告的撤诉申请中屡遭引用作为抗辩。在AI技术不断发展的今天, AI技术提供者也可以对模型与算法本身进行限制, 从而进一步降低其输出数据与训练数据之间的相似程度, 从而规避侵权风险。
2. 生成式人工智能的个人信息保护问题
如何最大发挥个人信息的经济效益并平衡个人权益保护, 对任何AIGC服务提供者来说都是难题。早在今年4月份, 路透社爆出意大利个人数据保护局宣布禁止使用ChatGPT, 因其涉嫌违法收集小于13岁的儿童的个人信息。目前, ChatGPT在意大利地区已经恢复使用, 但在进入聊天界面前设置了弹窗, 用户必须确认其已满18岁, 或已满13岁且获得父母/监护人的同意。就在不久前的7月13日, 美国联邦贸易委员会召开听证会, 对OpenAI公司存在的隐私安全、消费者权益相关的潜在风险进行调查。
本次出台的《暂行办法》强调了AIGC服务提供者的个人信息保护义务, 并与《个人信息保护法》实现联动。重点个人信息保护义务如下:
(1) 模型训练阶段, 收集个人信息应当具备合法基础并符合其他法律要求(第7条)
本条对应《个人信息保护法》第13条等的义务, 即要求AIGC服务提供者确保模型训练时使用的个人信息均具有合法基础。
如上所述, AIGC服务语料库的训练数据一般来自于公开互联网, 且数据量庞大。追溯所有个人信息主体并取得他们的个人同意几乎没有可能。对于AIGC服务提供者而言, 能否可以援引《个人信息保护法》第13条(四)“在合理的范围内处理个人自行公开或者其他已经合法公开的个人信息; ”作为处理个人信息的合法基础便成为了关键。该合法基础需要关注信息公开的方式, 以及拟进行的处理的性质。
一方面, 对公有领域个人信息进行使用, 必须需要限于“合理的范围内”还不得“对个人权益产生重大影响”(第27条), 否则需要重新获得个人的同意。模型训练行为是否属于“对个人权益产生重大影响”、超出合理范围的处理行为?AIGC服务提供者可以主张, 模型训练行为本身并不针对任何个体, 训练过程打破了个人信息的个体颗粒度, 反倒不会体现某一个体的特征, 对个人权益产生的影响也较小。换言之, 这也促使AIGC服务提供者尽可能减少模型训练行为对个人权益的影响, 例如尽可能减少对原始数据的留存与重现, 对训练数据进行必要的去标识化或匿名化处理等, 否则AIGC服务提供者只能退而求其次, 诉诸高成本的“知情同意”合法基础。
另一方面, 处理个人信息需要履行告知义务。在难以触达所有用户的公开互联网中, 公告似乎是AIGC服务提供者能够选择的最可行方式, 但公告方式, 严格意义上而言不一定能覆盖所有相关个人, 其效果也存在不确定性。且值得注意的是, 《个人信息保护法》中并没有基于告知难度过高, 成本过大显不合理而豁免个人信息处理者告知义务的例外。
(2) 服务阶段, 收集使用个人信息应遵守个人信息保护义务(第9条)
在AIGC服务阶段, 个人信息保护义务主要有以下几个方面:
a) 知情同意(第9、11条)
AIGC服务过程中收集、对外提供用户个人信息的, 应当提供个人信息处理说明并获得用户同意(或满足其他的合法基础)。
b) 最小必要(第11条)
《暂行办法》要求AIGC服务提供者不得收集非必要个人信息。这可能涉及到服务注册登录阶段以及实际使用阶段, AIGC服务提供者收集的个人信息需与其所声明的且实际使用的业务场景相适应。
此外, 《暂行办法》对于输入信息、使用记录的留存时间进行了明确规定。要求AIGC服务提供者不得非法留存能够识别使用者身份的输入信息和使用记录。笔者推测, 《暂行办法》可能考虑到了AIGC服务提供者留存使用者的使用记录并进一步进行用户画像或进行其他模型训练的风险。当然, 这一条并非禁止AIGC服务提供者留存任何个人信息, 而是强调留存的合法前提在于: 用户没有主动要求撤回同意或删除相关信息, 且个人信息留存后具有与之适应的处理目的与业务场景。
c) 权利响应(第11条)
《暂行办法》对个人信息权利进行了重述, 即提供者应当提供及时、便捷有效的响应渠道以响应个人对个人信息的查询、复制、更正、补充、删除等个人信息权利的请求。
前述个人信息保护义务并非《暂行办法》首创, 而是《个人信息保护法》下的规定在AIGC服务领域的重述。但是, 如何在AIGC服务场景中落实个人信息保护的相关规定, 比如就用户向AIGC提供的个人信息, 如何回应用户的查询、复制等请求, 则还是一个有待实践的问题。
3. AIGC服务中的算法服务相关要求
几年来已通过了数部与算法相关的管理规定。从范围较广的“算法服务”, 到“深度合成类的算法服务”, 再到本文聚焦的“AIGC服务”, 有关算法立法在不断精细化。AIGC服务不但需要满足《暂行办法》下的特殊规定, 还必须遵守与算法服务相关的一般规定。
首先, 对于算法的披露义务。参见本文第四部分第2节有关算法透明度、准确性和可靠性要求的介绍。
其次, 对于算法的安全评估和备案义务。《暂行办法》延续了《互联网信息服务算法推荐管理规定》《互联网信息服务深度合成管理规定》中对于安全评估与备案义务的规定。也就是说, AIGC服务与其上位概念深度合成类服务, 算法推荐服务一致, 提供具有舆论属性或者社会动员能力的信息服务的进行备案。有趣地是, 作为备案前提, “舆论属性”“社会动员能力”的定义却并不明确。根据《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》下的定义, 开办论坛、博客、微博客、聊天室、通讯群组、公众账号、短视频、网络直播、信息分享、小程序等信息服务或者附设相应功能的, 均可以视为具有“舆论属性或社会动员能力”。一般认为, 渠道特征是重要的考量因素——即使受众很少, 但一旦渠道是较为公开的且面对不特定用户的, 都不能排除具有“舆论属性或社会动员能力”的可能。
算法备案监管已经提上日程, AIGC服务提供者可以趁《暂行办法》生效前夕进一步向监管征询了解备案问题。截止8月份, 网信办已经发表了4份算法备案清单(http://www.cac.gov.cn/2022-08/12/c_1661927474338504.htm), 以及一份深度合称服务备案清单(http://www.cac.gov.cn/2023-06/20/c_1688910683316256.htm)。已经备案的服务提供者、技术支持者基本仍限于主流的互联网信息服务公司。
最后, 对于生成内容的标识义务。《暂行办法》要求提供者按照《互联网信息服务深度合成管理规定》对图片、视频等生成内容进行标识。目前对标识的要去主要限于两类。一类是《互联网信息服务深度合称管理规定》第17条中所列举的可能导致公众混淆或者误认的生成内容。至于不落入前述条款的生成内容, 提供者不需要进行显著标识, 但应当提供给使用者标识功能以供其选择使用。
四、《暂行办法》下的热点问题
对于AIGC服务中经常被关注的问题, 《暂行办法》或多或少给予了回应。
1. 数据来源的合法性要求和判断
人工智能依赖三大要素, 即: 数据、算法和算力, 而数据则是人工智能研究和发展的基石。为训练出更加准确、可靠的模型, 需要大规模、高质量的数据作为养分, 以进行数据的分析、预测和决策。《暂行办法》第7条对AIGC服务提供者在开展预训练、优化训练过程中, 数据及基础模型的合法性进行了规制, 其要求数据来源必须合法, 不得侵害他人依法享有的知识产权及个人信息权益等。
训练模型的数据主要来源于公开数据、自有数据以及第三方数据。对于不同来源及类型的数据合法性判断, 所依据的法律及合规措施不尽相同, 例如, 在生成式人工智能的训练数据中, 企业可能使用了通过爬虫技术爬取的公开数据, 对于这些数据的使用是否合法, 则需要具体结合《反垄断法》以及《反不正当竞争法》等法律法规以及目前司法实践的相关要求, 避免对原始数据的权利人或平台数据的开发者造成侵权或其他权益上的损害; 又如, 训练数据中可能包含了他人的个人信息, 对于该等数据的收集及使用, 则应当遵守上位法《个人信息保护法》中有关获得个人信息主体的知情同意或其合法基础的相关规定; 再如, 若企业使用了未经许可他人享有著作权的作品进行数据训练, 是否构成《著作权法》规定的“合理使用”范围则值得商榷, 正如我们上文所提到的, 合理使用认定的过程往往很复杂, 且因具体情况而定, 特别对于AI技术这样的新兴行业, 短时间内无论是司法、执法机关亦或是AIGC服务提供者, 都仍在探索把握。由此则可能具有侵犯他人合法知识产权的风险, 企业应当注意规避相关风险。
2. 算法透明度、准确性和可靠性要求
算法透明是人工智能治理领域公认的原则, 其要求算法所有者对算法的机制、决策过程等进行披露和公示, 旨在保护公众的知情权。我国在《关于加强互联网信息服务算法综合治理的指导意见》中, 也强调了算法应用应当透明可释的原则, 在《互联网信息服务算法推荐管理规定》、《互联网信息服务深度合成管理规定》等规范中亦明确了算法备案、安全评估等监管和问责的手段。
相比于《征求意见稿》, 《暂行办法》删除了其17条对生成式人工智能提供者“提供可以影响用户信任、选择的必要信息”以及“人工标注数据的规模和类型, 基础算法和技术体系等”, 而是要求提升AIGC服务的透明度(第4条第5项)以及对算法机理等予以说明(第19条)。由此变化可以看出《暂行办法》相对降低了对AIGC服务提供者在算法透明度上的要求。其一, 实现算法完全透明存在技术上的难度, 即机器学习法存在“算法黑箱”, 算法的推演不完全依照人类逻辑, 会导致部分算法无法被完全解释; 其二, 算法通常属于企业的核心竞争力, 可能构成商业秘密或知识产权, 过分的公开披露企业算法的运作机制将可能破坏企业的市场竞争力, 影响企业的发展动力。尤其可见, 《暂行办法》相较于征求意见稿平衡了公众知情权与企业商业秘密、知识产权保护之间的关系。
同样, 相对于《征求意见稿》, 《暂行办法》适当降低了对训练数据质量的要求。《征求意见稿》第7条中要求“能够保证数据的真实性、准确性、客观性、多样性”, 但事实上, 要求训练的数据完全符合真实性、可靠性等要求, 对于服务提供者而言往往难以保证。首先, 由于加入模型训练的数据很多都源于公开领域, 而该部分数据可能良莠不齐, 不可避免会有事实性的错误或虚假内容等。其次, 即使数据准确, 也未必客观, 数据本身可能存在社会性的偏差和误解。
《暂行办法》将《征求意见稿》修订为“采取有效措施, 提供训练数据质量、增强训练数据的真实性、准确性、客观性、多样显示器设置专注性”, 则是更加符合AIGC服务领域的现实, 强调在数据训练过程中行为方式和主管因素。《暂行办法》适度放宽了生成式人工智能数据训练方面的具体合规要求, 从一定程度上减轻了服务提供者的相应责任, 也是更多的从实际的角度进行了考量。
3. 生成内容的责任
服务提供者需要对生成式人工智能生成的内容负有一定的责任。根据《暂行办法》第21条, “提供者违反本办法规定的, 由有关主管部门依照《中华人民共和国网络安全法》、《中华人民共和国数据安全法》、《中华人民共和国个人信息保护法》、《中华人民共和国科学技术进步法》等法律、行政法规的规定予以处罚; 法律、行政法规没有规定的, 由有关主管部门依据职责予以警告、通报批评, 责令限期改正; 拒不改正或者情节严重的, 责令暂停提供相关服务。”如下, 我们整理了服务提供者对人工智能生成的内容负有的义务及需要承担的法律责任。
五、结语
《暂行办法》在吸收有关部门、行业和公众对《征求意见稿》的意见和建议的基础上, 更加充分考虑了AIGC服务的技术特点和难点, 体现了国家坚持发展与安全并重, 在鼓励创新、支持新兴AI 服务领域发展的同时, 采取包容审慎的原则, 明确了AI 服务领域的安全底线, 同时也为AIGC服务企业的发展预留了的空间。这是我国对AIGC服务领域立法的一次积极探索, 未来可以预见, 将会有更加全面的监管治理体系形成。
对于提供AIGC服务的企业而言, 则需要在开展科技创新的同时, 提高自身的合规意识, 在数据的开发使用、用户权益保护以及生成内容的准确性、透明性等方面按照《暂行办法》的指引建立良好的合规体系。
注:
[7] Andersen et al v Stability Al Ltd. et Compliant ¶155“Defendants had access to but were not licensed by Plaintiffs or the Class to train any machine learning, AI, or other computer program, algorithm, or other functional prediction engine using the Works”
[8] Silverman Et Al V. Openai, Inc. Et Al ¶56-57 “OpenAI made copies of Plaintiffs’ books during the training process of the OpenAI Language Models without Plaintiffs’ permission, …Because the OpenAI Language Models cannot function without the expressive information extracted from Plaintiffs’ works (and others) and retained inside them, the OpenAI Language Models are themselves infringing derivative works…”
[9] 使用目的与特点、被使用作品的性质、被使用部分的比例与实质性、对市场或原作品的价值的影响。
[10] (2021)京0102民初37702号、(2019)粤03民初2836号等
[11] 《RequestforCommentsonIntellectualPropertyProtectionforArtificialIntelligenceInnovation》https://www.uspto.gov/sites/default/files/documents/OpenAI_RFC-84-FR-58141.pdf
[12] 《Comment Regarding RequestforCommentsonIntellectualPropertyProtectionforArtificialIntelligenceInnovation Docket No. PTO–C–2019–0038 Comment of Open AI, LP Addressing Question 3》
[13] “nobody looking to read a specific webpage contained in the corpus used to train an AI system can do so by studying the AI system or its outputs.”
[14] Andersen et al v Stability Al Ltd. et, Amended Motion to Dismiss, ¶2 “To be clear, training a model does not mean copying or memorizing images for later distribution. Indeed, Stable Diffusion does not “store” any images. Rather, training involves development and refinement of millions of parameters that collectively define—in a learned sense—what things look like. Lines, colors, shades, and other attributes associated with innumerable subjects and concepts.”
[15] Andersen et al v Stability Al Ltd. et Compliant ¶93 “none of the Stable Diffusion output images provided in response to a particular Text Pr