
2021年12月31日,信安标委发布了《网络安全标准实践指南——网络数据分类分级指引》(“正式稿”)。文件名和内容都发生改动,以至于笔者最初以为这是一份新文件。但是根据不变的标准号和支持单位,我得出结论,其实这份文件是2021年9月30日征求意见的《网络安全标准实践指南——数据分类分级指引(征求意见稿)》(“草稿”)的正式稿。根据该征求意见稿,我曾经写过【金融机构数据分级分类怎么做?】。因此,笔者认为有必要对比一下正式文件到底做了哪些实质性的修改,对未来开展数据的分类分级工作又有何影响。
最让我惊喜的是,也许起草组的老师真的看到了我之前的推送中将金融行业的其他分类分级标准与指引进行比较(见下图)。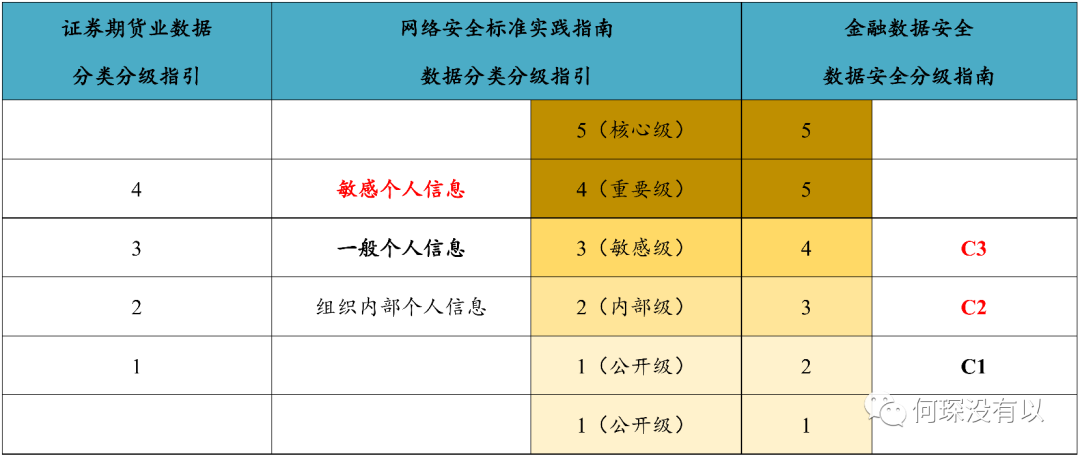
了解了不同文件分类分级标准不同给实务带来的困扰,在正式稿中,专门用了一个附件来解决文件间协同的问题(见下图)。这将大大提升企业进行数据分类分级的效率。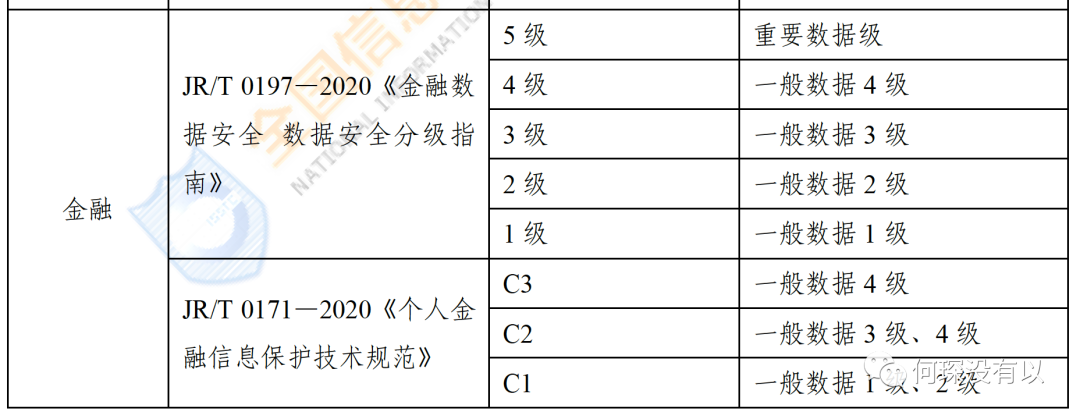
一、范围及定义?
(一)数据到网络数据
从文件名就能看出最显著的变化,由“数据”变为“网络数据”。与《网络数据安全管理条例(征求意见稿)》保持一致,正式稿网络数据定义为任何以电子方式对信息的记录,简称为数据。而草稿中的定义为任何以电子或者其他方式对信息的记录。因此,本规范不再调整以纸质等非电子方式存储的数据。
(二)其他定义变化
草稿 | 正式稿 |
国家核心数据是关系国家安全、国民经济命脉、重要民生、重大公共利益等的数据。 | 核心数据,即国家核心数据,是指关系国家安全、国民经济命脉、重要民生、重大公共利益等的数据。 |
Note:表述调整,不理解为何要与《数据安全法》表述不一致。 | |
公共数据是公共管理和服务机构在依法履行公共管理和服务职责过程中收集、产生的数据,及其他组织和个人在提供公共服务中收集、产生的涉及公共利益的数据。 注:公共管理和服务机构,通常包括各级党政机关、具有公共管理和服务职能的企事业 单位。 | 公共数据是国家机关和依法经授权、受委托履行公共管理和服务职能的组织(以下统称公共管理和服务机构),在依法履行公共管理职责或提供公共服务过程中收集、产生的数据。 注1:公共管理和服务机构,包括各级政务机关、事业单位,其他依法经授权或受委托 管理公共事务的组织,以及供水、供电、供气、公共交通、教育、卫生健康、社会福利、环境保护等提供公共服务的组织。 注2:本实践指南给出的公共数据是广义概念,实际使用时也存在狭义的公共数据,即 仅将提供公共服务的组织在公共服务过程中收集产生的数据作为公共数据,将政务机关履职过程中收集产生的数据作为政务数据。 注3:公共数据通常不包括组织专有的知识产权数据和商业秘密。 |
Note:进一步明确公共数据的定义。 | |
法人数据是组织在生产经营和内部管理过程中收集和产生的数据。 | 组织数据是组织在自身的业务生产、经营管理和信息系统运维过程中收集和产生的数据。 |
Note:扩大组织数据的范围。 | |
(三)新增定义
正式稿还新增一般数据、公共传播信息、商业秘密等定义。
二、数据分类分级原则
部分原则的名字变了,比如“时效性原则”改为“动态调整原则”,“自主性原则”改为“分类多维原则”。但笔者理解其内涵并未改变,甚至草稿中对原则的解释还更为清晰些。比如对“从高就严”的理解,正式稿中只适用于分级不适用于分类,但是他的分类逻辑还是先优先识别个人信息、公共数据等。因此,原则部分可以参考之前推送中的解读【金融机构数据分级分类怎么做?】,于此不再赘述。
三、数据分类分级框架
这部分被完全修改了,就是删掉重写了。
(一)数据分类框架
采用了面分类法,给出了多个维度。同时强调也可以采用线分法。

原来草稿只有一条路,先看是不是个人信息,再看是不是公共数据,最后看是不是法人数据,剩下的就都是一般数据。
现在正式稿并不没有给出一条唯一的路,只是给了几种分类思路,可以分成(1)个人信息/非个人信息;(2)公共数据/社会数据;(3)公共传播数据/非公共传播数据;(4)各行业数据;(5)对经营者来说,正式稿建议先识别出用户数据,再将剩余的数据从便于业务生产和经营管理角度进行,附录A将经营者数据分为用户数据、业务数据、经营管理数据、系统运行和安全数据。

按照上图的解释,届时可能某一个数据可以具备类似身份证的含有多个分类字段的代码。比如:111225,即1|0|0|22|5,代表这个个人信息,是个人信息,也是社会数据,是非公共传播数据,是代码为22的行业,即金融行业的数据,是代码为5的经营者数据,即安全数据。
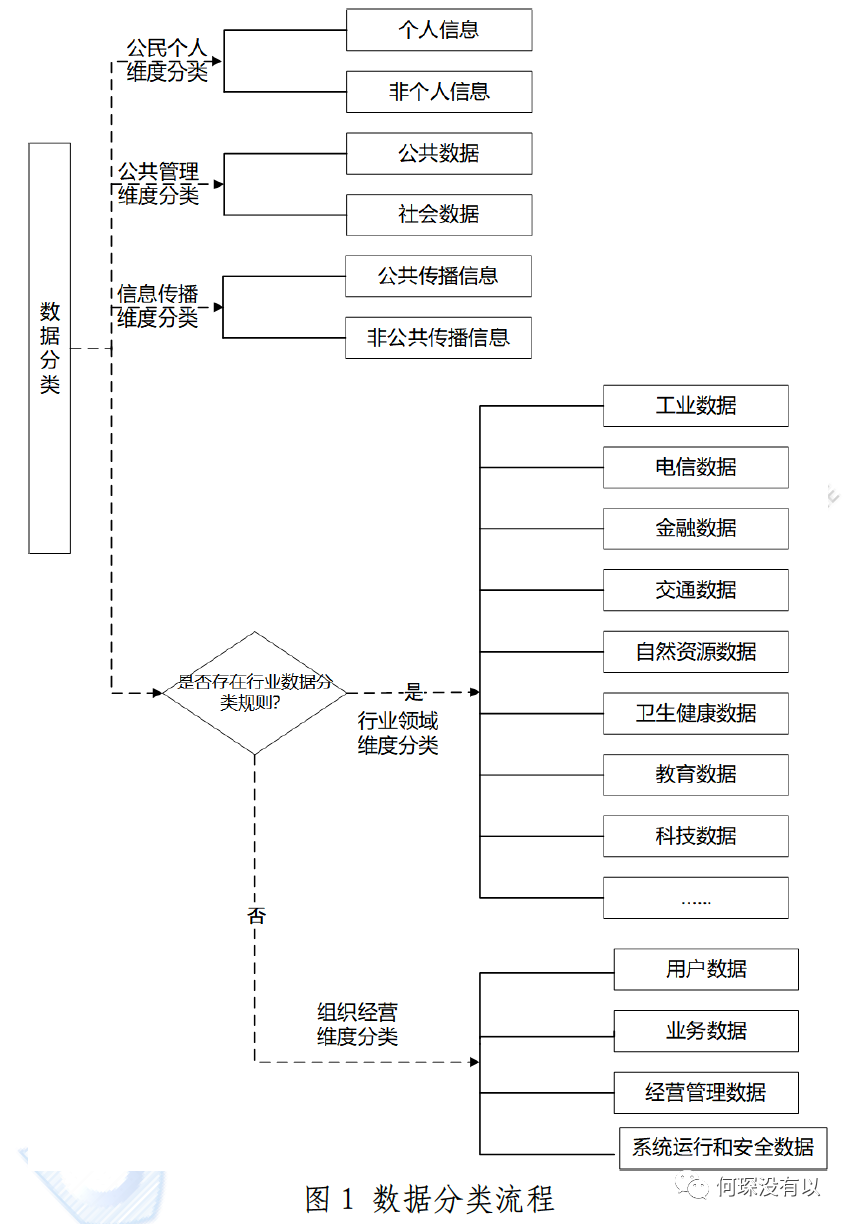
这种分类方式确实更加多元。
(二)数据分级框架
《数据安全法》把数据分成了三级:核心数据、重要数据和一般数据。正式稿说,一般数据可能涵盖太广了,于是6.3部分给了些更细的划分方法(分了四级)。正式稿也说,重要数据和核心数据怎么分级,这个指南管不了层级那么高的数据,以相关重要数据目录的定级为准。
四、数据分类
接下来正式稿讲了具体如何进行数据分类,每个类型的数据都是两个步骤,一如何识别是否属于该类数据,如果是该类数据又在内部如何分类。
以个人信息为例,正式稿给了识别和关联两个路径,随后将个人信息分为了16类。也许未来在个人信息这个分类字段就是从00到16,00代表不是个人信息,后面01~16代表着这16类个人信息。
公共数据和公共传播数据的分类也是相同的逻辑,先识别,再分类。并无难以理解之处。因此不再赘述,到时候去看原文就好了。
五、数据分级
(一)数据分类流程
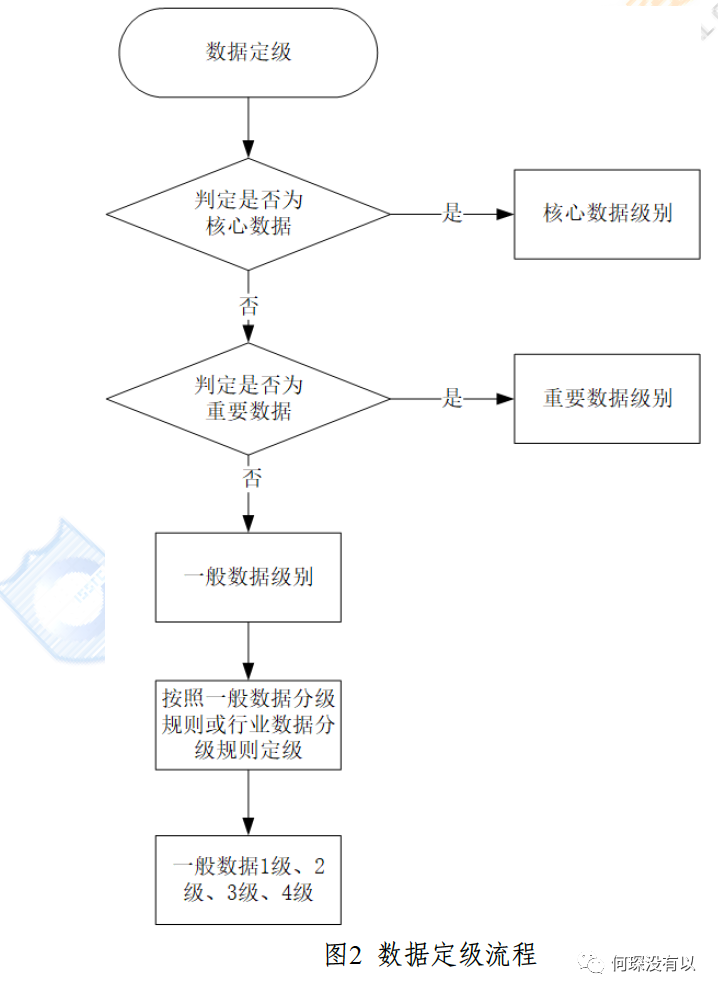
这个逻辑还是没变化,先识别核心数据、再识别重要数据,这些数据的定级听重要数据目录的。一般数据内部再自己分1到4级。
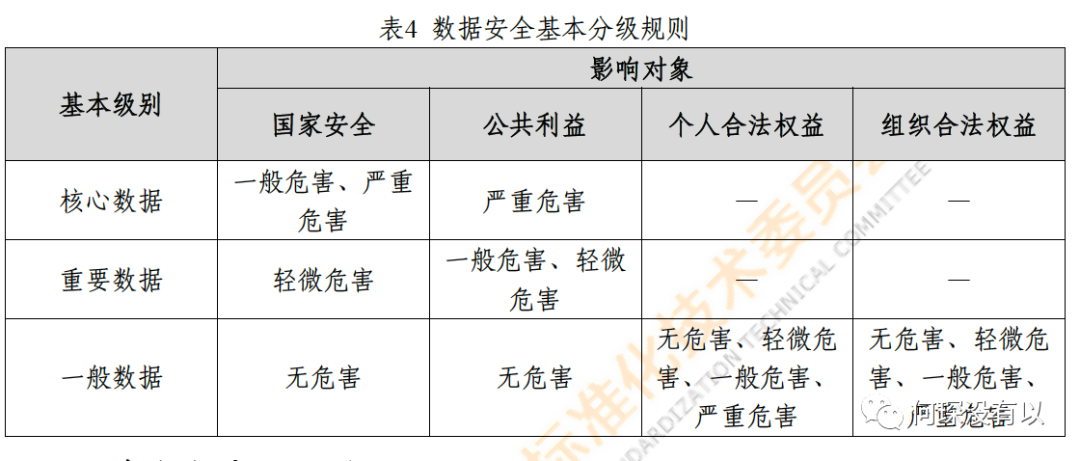
从上面这张图也可以看出来,一般数据是不会影响公共利益和国家安全的。而一般数据对个人或组织的严重、一般、轻微或无危害正好也对应了(4级别到1级)
等级 | 影响程度 |
1 | 数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用,不会对个人合法权益、组织合法权益造成危害。1 级数据具有公共传播属性,可对外公开发布、转发传播,但也需考虑公开的数据量及类别,避免由于类别较多或者数量过大被用于关联分析。 |
2 | 数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用,可能对个人合法权益、组织合法权益造成轻微危害。2 级数据通常在组织内部、关联方共享和使用,相关方授权后可向组织外部共享。 |
3 | 数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用,可能对个人合法权益、组织合法权益造成一般危害。3 级数据仅能由授权的内部机构或人员访问,如果要将数据共享到外部,需要满足相关条件并获得相关方的授权。 |
4 | 数据一旦遭到篡改、破坏、泄露或者非法获取、非法利用,可能对个人合法权益、组织合法权益造成严重危害,但不会危害国家安全或公共利益。4 级数据按照批准的授权列表严格管理,仅能在受控范围内经过严格审批、评估后才可共享或传播。 |
(二)个人信息定级
此外,对于个人信息的定级,正式稿还给出了相关建议。比如敏感个人信息应当定级为4级,并且给出了如何识别敏感个人信息更加详细的方法和列表。无论相当于《个保法》还是《个人信息安全规范》都更进一步,很有参考意义。
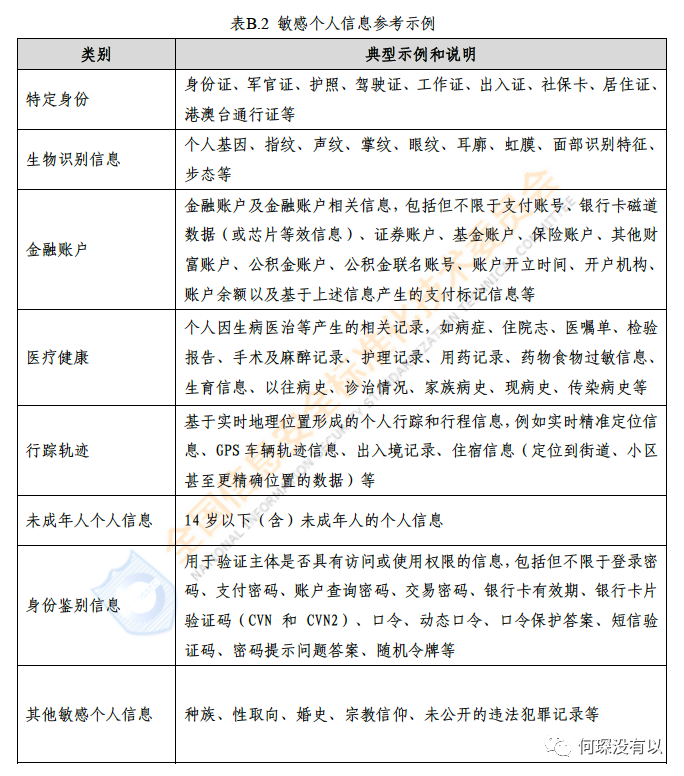
此外定级建议还有:(1)一般个人信息不低于2级;(2)组织内部员工个人信息不低于2级;(3)有条件开放/共享的公共数据级别不低于2 级,禁止开放/共享的公共数据不低于4 级。
(三)衍生数据定级
此外,正式稿将衍生数据分为:脱敏数据、标签数据、统计数据、融合数据,并给出相关定级建议。
数据类别 | 类别定义 | 数据示例 | 定级建议 |
原始数据 | 是指数据的原本形式和内容,未作任何加工处理。 | 如采集的原始数据等 | 原始数据可按照上文介绍的方法进行定级,衍生数据级别原则上依据就高从严原则,对照加工的原始数据集级别进行定级,同时按照数据加工程度也可进行升级或降级调整。 |
脱敏数据 | 对数据(如个人信息)按照脱敏规则进行 数据变形处理后的新数据。 | 如去标识化的手机号码( 如138*******6)等,个人信息去标识化、匿名化处理后的数据属于脱敏数据。 | 脱敏数据级别可比原始数据集级别降低,去标识化的个人信息不低于2 级,匿名化个人信息不低于1 级。 |
标签数据 | 对用户个人敏感属性等数据进行区间化、分级化、统计分析后形成的非精确的模糊化标签数据。 | 偏好标签、关系标签等。 | 标签数据级别可比原始数据集级别降低,个人标签信息不低于2 级。 |
统计数据 | 即群体性综合性数据,是由多个用户个人或实体对象的数据进行统计或分析后形成的数据。 | 如群体用户位置轨迹统计信息、群体统计指数、交易统计数据、统计分析报表、分析报告方案等。 | 统计数据如涉及大规模群体特征或行动轨迹,应设置比原始数据集级别更高的级别。 |
融合数据 | 对不同业务目的或地域的数据汇聚,进行挖掘或聚合。 | 如多个业务、多个地市的数据整合、汇聚等。 | 融合数据级别要考虑数据汇聚融合结果,如果结果数据汇聚了更多的原始数据或挖掘出更敏感的数据,级别需要升高,但如果结果数据降低了标识化程度等,级别可以降低。 |
(四)重新定级
重新定级的情形与草稿差距不大,不再重复。定级变化的参考规则,见下图。
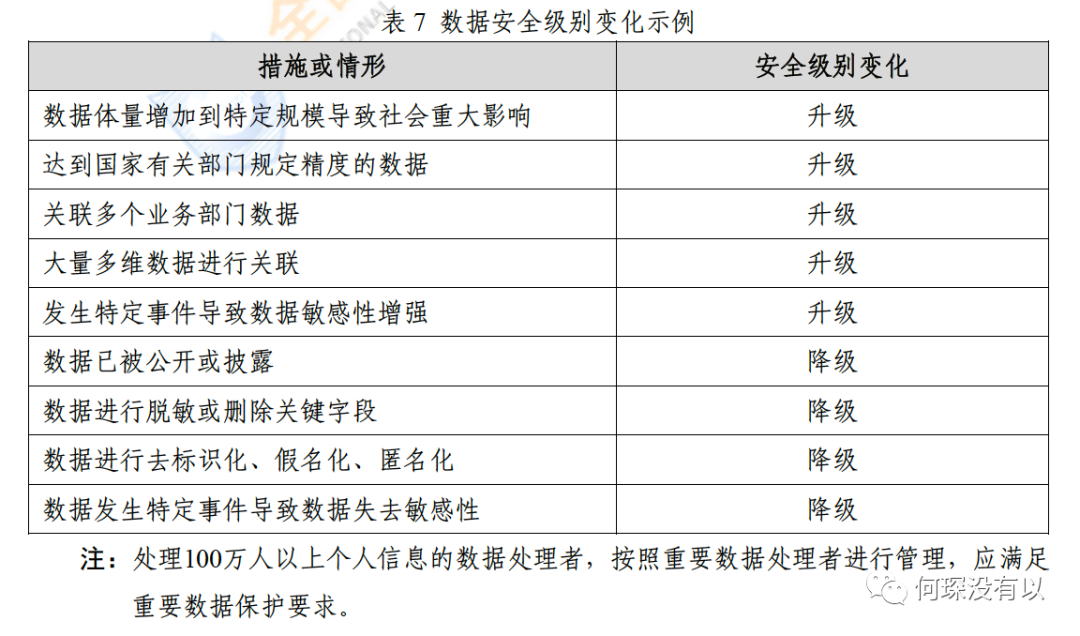
注意看注释,《数安条例》100万以上个人信息处理者视为重要数据处理者管理的要求被生效的指引保留了。
六、数据分类分级框架
分类分级的流程也没有大变化,梳理数据资产,先分类,再分级,再根据分类分级进行差异化管理。