人工智能(AI)通过降本增效、提高成功率和拓展创新空间, 正在从根本上重塑生物新药研发。例如, 传统研发一款新药通常需要10年时间和10亿美元以上的投入, 其中仅早起研发就需要4-5年, AI 的介入能将这一时间缩短至18个月左右。[1]
近年来, 中国药企形成了“AI赋能研发+国际多中心临床(MRCT)验证+跨境授权(License-out)”的创新出海新范式。通过AI大幅缩短靶点发现与分子优化周期, 结合符合国际标准的MRCT数据, 中国原创药在安全性与有效性上获得了全球监管及跨国药企的高度认可。
在实践规模上, 这一模式已进入爆发期。2025年, 中国药企对外授权交易总额突破1,300亿美元, 占据全球相关交易额的近50%, 授权管线数量超过150项。[2]以科伦博泰、百利天恒、英矽智能等为代表的领军企业, 通过与默沙东、BMS、阿斯利康等巨头达成数十亿乃至百亿美元级的合作, 成功实现了从底层算法创新到全球商业价值兑现的闭环。
与此同时, 在当前地缘政治博弈与数字化研发转型的双重背景下, 中国生物医药企业借助AI开展跨国新药研发及多中心临床研究, 正面临着前所未有的复合型法律合规挑战。
第一, 境内监管。中国对于人类遗传资源出境、个人信息跨境流转、以及《生物医学新技术临床研究和临床转化应用管理条例》下算法伦理审查与临床研究备案均设有严苛的监管程序;
第二, 境外审查。美国《生物安全法案》(BIOSECURE Act)高压下, 对中国背景实体施加了供应链“去风险化”(De-risking)与物理隔离的要求; 与此同时, 美国食品药品监督管理局(FDA)对AI辅助决策的算法可解释性与潜在偏见提出了更高的审查标准;
第三, 在AI药物研发(AI-Driven Drug Development, AIDD)中, 法律通常滞后于技术的突破, 然而各类新兴风险——包括算法偏见、AI幻觉、伦理问责等——却常常在既有法律规则形成之前便已实质性存在。
第四, 跨境交易。跨国合作中, 围绕算法逻辑等知识产权所有权、数据主权归属问题, 已成为双边博弈的焦点, 进一步加剧了交易结构的法律复杂性。
从以下四个维度, 本系列文章旨在赋予中国生物医药企业一双“慧眼”, 识别AI新药研发商业化的市场蓝海中的法律合规风险“暗礁”。
1.地缘政治与准入篇: 重点分析《生物安全法案》对AIDD许可合同条款的改变, 以及“清洁子公司”下的实质性运营合规等问题。
2.数据合规篇: 重点解析个人信息保护与数据安全视角下人遗办(HGRAC)审批备案、网信办(CAC)安全评估, 以及联邦学习、隐私求教计算等技术解决方案。
3.算法监管与伦理篇: 深度解读《生物安全法》《生物医学新技术临床研究和临床转化应用管理条例》《科技伦理审查办法(试行)》等对AI算法风险评估报告的具体要求及临床责任划分。
4.核心资产博弈篇: 探讨许可与商业权益合同中AI模型所有权与数据权等实务操作。
如您希望与作者对本主题相关问题进行进一步深度讨论, 或索要具体落地文件(例如《AIDD合规尽调清单》), 请与本文作者联系。
AI新药出海法律实务
第四篇: 许可与商业权益合同新重点条款
在传统的新药许可中, 知识产权的核心是化学分子式。然而, 在 AI新药研发许可交易中, 知识产权重点已转移至具体的分子式转为更为抽象的算法。相应地, 合作许可项目的博弈点不仅是“谁拥有这款药”, 而是“谁拥有药物模型和模型的持续改进权”与“谁拥有数据权”。本文以下就Ai新药研发许可交易中的“模型”“数据”相关的新重点条款进行剖析。
一 AI新药研发模型
(一) 背景”“前景”“衍生”三权
在 AI 驱动的新药研发时代, 交易各方所关注的知识产权法律框架已从“以分子为中心”转变为“以算法智能为核心”的模式。而在交易文件中, 知识产权不再仅仅涉及化学结构, 而是数据输入、计算模型与衍生生物学know how的结合。AI新药研发模型中, 基础、前景与衍生知识产权的界定不仅决定了一款药的归属, 更决定了AI新药研发的未来能力。
背景知识产权(Background IP)在 AI新药研发许可场景中本质上是“生成引擎”与“训练基石”, 涵盖了许可方在合作开始前已存在的专利算法、神经网络架构, 以及用于模型训练的专有生物学数据集。作为许可方的中国企业必须严格界定背景知识产权的边界, 以防止其被纳入前景或衍生知识产权。然而, 实践中的难点在于, AI新药研发场景下的背景知识产权不是静态的, 而是一种“活的”资产。换言之, 背景知识产权(Background IP)已从一种“固态的知识成果”演变为一种“具有自我迭代能力的动态系统”。这种“活”的特性源于AI模型对数据的持续学习以及算法结构的不断优化。作为解决方案, 许可方可采用“交付时的快照(snapshot at delivery)”“版本锁定”(Version Locking)技术, 精确定义哪一次迭代的模型构成背景知识产权。具体而言, “交付时的快照”是应对 AI资产动态演化特性的核心法律工具, 其本质是将“流动”的技术状态在合同生效日进行“瞬间冻结”。在这一机制下, 许可方在交付 AI 算法时, 不仅要交出代码, 更要记录该时刻模型的权重参数、神经网络架构以及性能基准。快照可以为许可方和被许可方划定一条清晰的法律红线: 红线之前的一切属于许可方的背景知识产权, 而红线之后产生的任何进化或变异, 则进入前景知识产权或衍生知识产权的博弈范畴。这种做法有效地解决了 AI 新药研发中常见的“权属模糊”难题, 确保了许可方在未来的其他项目中, 能够通过审计快照来证明其技术的独立性与合法性。
前景知识产权(Foreground IP), 即合作产生的新知识产权。具体而言, 是指合作期间生成的候选新分子(NMCs)及其独特的参数。传统药物研发许可中前景知识产权往往由交易方共有, 但AI新药研发许可场景下交易双方倾向于进行“功能性拆分”: 被许可方(跨国大药厂)通常拥有最终产生的物理分子和临床数据, 而许可方(AI 药企)则保留“模型调整权”——即在寻找该分子过程中产生的特定微调(Fine-tuning)和权重优化。这种区分至关重要, 它能防止被许可方主张对AI 预测同类靶点能力的改进拥有所有权, 如果不这样做, 将实质性“冻结”许可方的AI算法, 导致其无法在同一治疗领域与其他伙伴合作。换言之, 通过功能性拆分, 药厂获得了“药”, 而 AI 药企保留了“大脑的进化成果”, 从而实现了双方商业利益的最大化平衡。
许可方和被许可方的终极博弈在衍生知识产权(Derivative IP)的归属, 即双方对“持续进化权”与“跨项目研发”权属的谈判确定。 AI药物研发语境下, 衍生知识产权通常涵盖从合作数据中提炼出的对核心AI算法的改进, 即便这些改进适用于当前项目之外的药物。AI算法从被许可方数据中所获得的“学习成果”究竟属于许可方的技术改进?还是属于被许可方的项目衍生技术?为解决这一冲突, 许可交易文件中可引入“反馈循环”和“无损学习”(Non-invasive Learning)条款, 即允许 AI算法提取“通用逻辑”(归许可方所有), 同时确保“特定洞见”(归被许可方所有)不被泄露。为落实上述条款机制, 许可方必须确保 AI算法更新后的权重不会“记住”被许可方的保密化学空间。此外, 通过设置“排他性禁区”, 确保许可方在保留更聪明模型的同时, 在合同上被禁止在特定治疗领域内将这种新获得的新智能对抗作为数据贡献者的被许可方。
(二) 反向授权
衍生知识产权反向授权(Grant-back) 是指在许可协议中, 被许可方在利用许可方的原始技术进行研发过程中, 如果产生了任何改进、优化或衍生发明, 必须将这些新成果的所有权或使用权“授权回”给原始许可方。在 AI 驱动研发的背景下, 反向授权通常表现为: 大药厂在使用中国 AI 药企的模型时, 对模型算法的改进或发现的新相关数据, 必须反向授权给中国药企, 以确保其平台能力的持续进化。
为便利作为许可方的中国药企获得反向授权, 中国药企应坚持“平衡互惠”与“范围锁定”原则。在条款起草中, 中国药企可要求被许可方授予中国药企一份全球性的、永久的、免许可费的、非排他性的许可, 允许中国药企将这些衍生改进整合进其核心 AI 算法。这一利益平衡机制, 既不剥夺大药厂对特定候选药物(前景知识产权)的所有权, 又可保证中国药企的算法不会因为与该药厂的合作而产生“技术断层”或“法律封锁”。
最为应对, 中国药企应设置精细的“排除清单”和“数据脱敏”机制。一般而言, 反向授权仅限于“平台级改进”(如模型权重的优化、通用的算法提升), 但排除与被许可方特定商业秘密、具体靶点信息或独家化学空间相关的敏感数据。这种“算法归许可方, 数据归被许可方”的切分逻辑, 能够有效缓解大药厂对技术外泄的担忧。此外, 中国药企还应争取“转授权(Sublicensing)”的权利, 确保通过反向授权获得的AI算法能够合法地应用于未来与其他合作伙伴的项目中。通过这种策略, 中国药企不仅保护了现有的知识产权边界, 更通过每一次外部授权实现了 AI 模型的“借力进化”。
(三) 不可分割的改进
确定知识产权归属的前提是可分割性。AI 新药研发中, 对可分割性的界定是区分“算法进化”与“项目成果”的重要因素。不可分割的改进本质上是 AI 算法的自生长, 涉及到底层算法权重的重新配置。对于中国药企而言, 这类改进必须紧握手中, 因为它们构成了公司核心竞争力的增量。如果允许这类改进被若干被许可方分散拥有, 将对中国药企在未来项目使用AI算法进行研发产生法律障碍。因此, 实务中通常通过“侵权测试”来判定: 即如果一项改进的使用必然会触碰许可方的基础专利, 则其被视为不可分割, 应自动回流至许可方。
相反, 可分割的改进代表了合作的“果实”, 如具体的新分子结构或生物靶点洞见。这些成果是使用 AI 算法后的产出, 而非算法本身的升级。实践中, 将可分割的改进成果划归被许可方是维持合作关系的必然选择, 因为大药厂支付数亿美金正是为了获得这些可独立受专利保护的药物资产。然而, 中国药企应警惕如何防止被许可方将“可分割改进”申请一些宽泛的“应用专利”来反向限制许可方AI算法的自由操作(FTO)。因此, 在许可交易文件中, 中国药企应不仅注重区分两者的权属, 还必须设置“互不干扰”和“反阻碍”条款, 确保AI算法的迭代更新不受被许可方的上述可能的限制。
核心差异对比表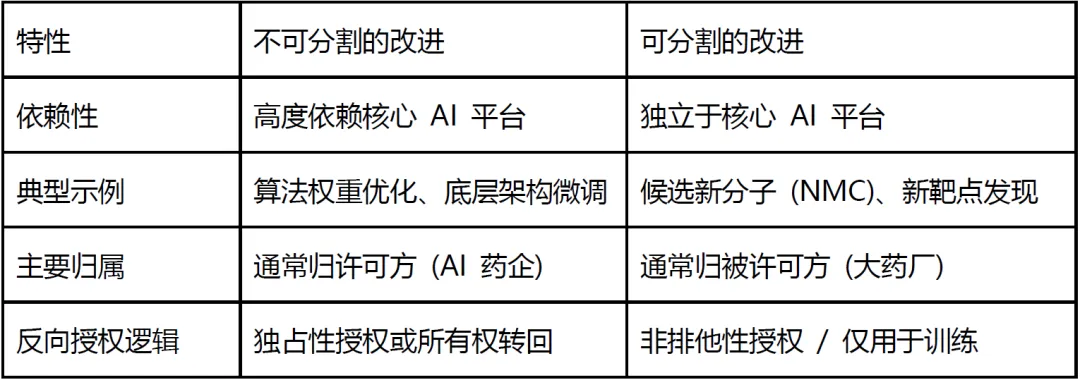
二 除外研究与数据权
如前所述, 在AI新药研发许可场景下, 数据“所有权”是至关重要的动态核心资产。限于篇幅, 本文选取“除外研究”条款论述数据权。
(一) “除外研究”条款
在许可交易文件中, “除外研究”(Excluded Study)条款旨在明确哪些特定的研究活动不属于双方共同管理和资金分担的范围。通常, “除外研究”包括在协议签署前已启动的试验、研究者发起的试验(包括Investigator Sponsored Trial和Investigator Initiated Trial), 或授权方为探索特定适应症或内部专利组合而进行的独立研究。通过剔除这些活动, 双方得以保留独立操作自主权, 确保一方独立的科研探索或先前的法律义务不会不必要地消耗合作预算, 也不会触发联合管理委员会(JSC)复杂的集体决策程序。
(二) 数据污染
实践中, “除外研究”条款实施的难点在于如何管理“数据溢出”及其对核心合作资产的影响。由于 FDA 或 NMPA 等监管机构将药物视为单一的药理实体, 任何从“排除”的研究中出现的安全性信号或疗效失败, 在法律和监管层面都会引起关注。因此, 许可交易文件中应设定安全数据交换(Security Data Exchange)协议和监管引用权(Rights of Reference)来解决这一问题。这些机制确保了虽然研究在资金和操作上保持独立, 但产生的数据可用于注册申报和说明书扩展, 从而避免一方因未参与控制或资助的研究触发临床暂停而陷入被动。
除安全性风险外, 界定不明的排除研究还会导致疗效稀释和监管冲突。如果一方在相关适应症中进行了一项效力不足或设计不当的独立研究, 由此产生的“失败”数据将成为公共记录, 削弱医保支付方、医生和投资者对该药物整体治疗潜力的信心。此外, 如果排除研究的结果与核心合作研究的结果相矛盾(例如在次要终点或生物标志物反应方面出现差异), 可能会迫使最终产品标签中加入“使用限制”条款。这不仅限制了商业推广团队宣传其“同类最佳”(Best-in-class)地位的能力, 还直接缩减了适用意向人群, 从而降低了作为特许权使用费计算基础的净销售额。
此外, “除外研究”范围的约定不明, 将对核心知识产权的完整性构成威胁。若独立研究的边界未能得到严格划定, 合作伙伴极易在平行研究中发现核心管线的新用途或关键生物标志物, 并据此主张对该“新增知识产权”(Arising IP)拥有独立所有权。这种权属争议往往会导致“阻碍专利”(Blocking Patents)的僵局, 使核心合作项目面临两难境地: 若不向合作伙伴支付额外许可费或面临侵权诉讼, 则无法实现商业化产品的优化与迭代。为防止此类数据与权利的“交叉污染”, 中国药企应在许可交易文件中构建“防火墙”机制, 建立强制性的受控数据交换协议以确保信息流动的可追溯性; 实施精确的适应症切分(Indication Carve-outs)以在临床用途上划定物理隔离带; 以及设定对独立研究产出的公开信息披露拥有共同审阅权。
(三) 数据“所有权”
AI新药研发许可与商业权益项目中, “除外研究”(Excluded Study)产生的数据“所有权”(Data Ownership), 体现了“投资原则”与“资产保护”之间复杂的博弈。从法律层面看, “出资即拥有”(Funded-by, owned-by)是基本原则, 即发起方(通常是被许可方)因为承担了100%的财务风险, 从而拥有该研究产生的原始数据和临床研究报告的唯一所有权。这种法律上的隔离旨在为发起方提供“资产纯净性”, 确保这些独立研究成果不会受到大合作框架下联合管理或收益分成机制的约束, 这对于发起方未来进行资产剥离或寻求第三方合作至关重要。
然而, 实操中数据的“所有权”往往与“使用权”在功能上是分离的, 以防止发起方利用独立数据绑架核心合作项目。即使数据归发起方独立所有, 非发起方的合作伙伴几乎总会要求获得一项永久、不可撤销且免许可费的“监管引用权”(Right of Reference), 允许合作伙伴将除外研究的数据提交给卫生监管机构, 用于支持核心合作产品的安全性评价或说明书标签扩展。如果没有这种交叉访问权, 核心产品可能会面临“数据断层”而推迟上市, 使得独立研究在无意中变成了共有资产的障碍。
结语
在AI驱动的新药研发浪潮下, 底层资产的逻辑已完成从“化学原子”向“数据比特”的深刻跨越。当“模型进化”与“数据所有权”成为交易的核心要素, 合同条款的颗粒度将直接决定合作的生死。无论是严密的“防火墙”机制, 还是前瞻性的“回授许可”设计, 其核心目的均在于确保创新链条的连续性。未来的成功合作, 将属于那些能够前瞻性地界定算法边界、并能通过精细化条款实现风险对冲与价值共享的先行者。
注释
[1] Pathak A, Theagarajan R, Rizqi MM, et al. AI‑enabled drug and molecular discovery: computational methods, platforms, and translational horizons. Discover Molecules. 2025;2:32. doi:10.1007/s44345-025-00037-5.
[2] 季媛媛: “2025中国创新药BD交易‘爆单’ 一年狂揽超1300亿美元”, 证券时报网, 2026年1月5日, https://www.stcn.com/article/detail/3569424.html。
AI新药研发出海法律实务——第四篇: 核心资产博弈篇——许可与商业权益合同新重点条款
作者:潘永建 朱晓阳来源:通力律师事务所

人工智能(AI)通过降本增效、提高成功率和拓展创新空间, 正在从根本上重塑生物新药研发。